


Computer used to be a job, now it's a machine; next up is Analyst
"An analyst on every desk and in every home."


This year started with a promise to do more experiments. And partly that’s why over the past few weeks I’ve written rather a lot about AI and various ways to think about it. But I think it’s useful to see, practically, how it works. So I did a bunch of experiments on what I can do now using it, and here’s a look at what I think might be coming!
At the dawn of the computing age, the microprocessors of yore started and created a deterministic revolution1. The logic gates were severe in what they allowed. What you input determined what the output would be, and it was demonstrably and repeatably the same.
In fact, this was the problem with applying AI to things until very recently. While you saw plenty of applications in things like advertising or newsfeeds, there was much less in areas that couldn't survive without higher degrees of accuracy. Like medicine, or law enforcement. Things that required multiple sigmas of accuracy were, and still are, AI’s achilles heel.
That’s because it was trying to act like a black-box calculator, to do repeated mechanical-ish manoeuvres to a sufficient degree of accuracy. Instead, I like to conceptualise LLMs as a fuzzy processor. One that does better with analysis, which is a service job. It already doesn’t have high degrees of accuracy in many parts of its stages, but it does require skilful combination of a large amount of information2.
We can start small, treat them like Legos. What arguably langchain and others are starting to help with. But legos have to be built manually. There's an upper limit to how sophisticated you can make them, even though there are moon-sized battle ships people build. The trick is to try and get the pieces to assemble themselves.
Today they hallucinate and sometimes create weird outputs, especially when done in a conversational mode and on zero-shot mode. But we’re treating these products, and its variants, today like they’re computers. Ask Bing, Sydney, ChatGPT. Make it write poetry, ask it questions about historical esoterica.
I think this is probably why we try and anthropomorphise huge chunks of it. Instead if we think of them as processors to which we outsource parts of thinking, the errors become bugs to correct. This is why why I like the fuzzy processor analogy3. The power with LLMs, amazing as it seems today, isn’t limited to producing poems on demand. It’s when you link 10,000 of them together, like processors, that true magic can happen!
How many Google searches do you do on a daily basis? How about ChatGPT requests? 100? 500? All in human scale. All the while in the last minute your processor probably got around 25,000 pings without doing a lot.
It’s the first time in like 20 years there’s the possibility to build something truly epic, an Operating System to build a whole new category. Let’s start with three examples of what I’m talking about, bearing in mind these are like the Hello World programs we wrote on DOS!
Three examples
A short wonky sidestep to see how we might create lego-blocks. Here are three examples of the types of things I tried to try and test the capabilities a bit myself. (Feel free to jump to the next section if you don’t find this interesting, or if you need more screenshots it’s in the footnotes.)
Find an answer by creating search entries, finding the top most important entries and topics related to your question, then summarising the top search links
We can now iterate queries and get real time insight on anything we like, and link the processor with real-world info.
I did it on travel plans for the family, with constraints on what we liked. But imagine what's possible here. We could search specific databases, like only scientific papers, we could preselect based on particular attributes, like author institutions or citations, and have an LLM summarise this for you. Or YouTube videos and transcribe them before summarizing.
Today, sometimes the search isn't very good. And the solution to this I found was to use another LLM call to extract any key entities or relevant information first, and refine further queries. Which means starting with just a search engine and an LLM, we now can basically use them to create, research and analyse multiple hypotheses and choose from amongst them4.
More here5!
Upload a document or a directory, figure out type(s) of files, and index them to do Q&A, or a recursively summarised answer to any query
Another thing I tried was finding more and more complicated ways to be lazy. In the course of writing Strange Loop I read a fair few papers, books, and many a boring website.
What most of this entails is of course trying to figure out the gist of what the docs actually say, and with a fair bit of back and forth to interrogate it. So I tried recursive summarisation (slicing text into chunks and summarising each bit separately, then summarising the summaries) and create embeddings to search the text, which works a treat! We can do the same thing with whole directories, where we can read all the files inside and do the exact same things6.
If primed appropriately, it can even do comparisons, and sign each chunk to make sure we have references!
(And if you're the type of person who reads Strange Loop Canon here's what it thinks you'd like about talent selection7.)
Unbundle a question into core elements, separate each entity, compute using Wolfram Alpha and summarise the results
For a large number of queries, it’s difficult to get a direct answer from GPT-3’s text autocomplete, because predicting the next token is a different thing to actually computing how something works.
To do this you can extract entities or ask the LLM to phrase specific questions in computational forms, and then pass it to Wolfram Alpha to have it answer the question.
The difficulty is mostly due to the fact that the types of questions I wondered about were not particularly computational, and the computational elements were “inherent” in many of the questions rather than the main point.

More here8 !
What’s missing still
The interesting thing in my explorations has been that it’s not that easy to figure out what’s possible and what’s not possible with these new fuzzy processors without a lot of trial and error. In order to process the data that comes in through them, they have to “know” about the world in which we all live.
Which means it’s not a simple processor, but actually a processor with a mini-world inside it. Most processors thus far separate out the thing they’re processing from the method they use, but here they’re intricately tied together.
If you really feel up to it, this is where people assume a Maxwell’s demon inside GPT-3, pulling its matrix strings to make the answers come true. But lest we anthropomorphise too much, this is also what allows us to use it as li’l modular stacks.
To deal with these mini-worlds is hard, because we don’t have an opcodes for them yet, no manuals on how to use them, and no pathways beyond the trial and error guesswork that we’ve collectively created over the past couple years.
Like, for most of the questions I asked, including many of the summary and Q&A questions, what is needed is a “constant monitoring” module, which can extract aspects of the answer that require computation.
A “constant monitoring” module, which would require a lot more regular output<>input from a standby LLM, isn’t easy today but it’s soon gonna become feasible.
Building it is going take us a couple years, but it’ll be worth it!
And so, to build your own personal analyst
Just like the original processors were weak and couldn’t do a whole lot, it’s in joining a whole bunch of them together that you get magic.
When we did it before, we got personal computers. And when we do it now, we’ll get personal analysts.
Link these all together, and we can already see it come to life, albeit in a simpler form. Someone who can:
Read and summarise from any document
Create questions that would be smart to get answers to, and then do Q&A on it
Check the answers against another set of text if needed
Compute things as needed, if the answers demand it
Check things which are unfamiliar on the internet, and summarise the answers
Write them in various formats that’s most impactful
And we can further add modules if you want to extend this to create a smarter analyst:
Add LLM modules to test the answers and summaries and check whether they “stack up” to any arbitrary ability
Make these modules fine-tuned for specific tasks - the ones checking answers need not be the same call as the ones creating the answers need not be the same ones that monitor the performance need not be the same ones that act as “librarians” to search and extract info from Google
Make the modules specific to your inputs, from personality to particular datasets, with “permission” to take certain actions on your behalf
And yes, a module to take whatever answer is produced and create a beautiful and evocative written output at the end of it - an essay, a picture, a poem, an elegy, and more!
Think about what these can do! In a business context, it can handle coding, customer interactions, writing reports, analysing dashboards, creating pretty much any type of content or editing it, and take actions to read/ edit/ write to a database of your choosing or send a Slack message or …..
Which brings me to my most surprising conclusion: Most errors with LLMs can be made better by adding even more LLM calls.
Fuzzy processors are the unlock to the next chunk of computation that we’ve been doing, even as we offloaded calculations to a machine. As costs decrease by 90% and again by multiples, these come closer to reality.
We’re starting to see this today. Companies like Consensus and Elicit are linking pieces together today to create actually valuable output that would’ve required an Research Assistant in the before days - helping research summarisation, search, figuring out new questions to ask, and more!
Like most automation, it substantially increases the potential for an individual to do far more than they could before.
There used to be “computers”, teams of women who computed complex numerical problems, who helped put us on the moon, and who were replaced by the amount of computation that exists inside our greeting cards.
A new machine here could be the replacement for “analysts” - teams of people who analysed complex problems, who helped produce many of the great innovations the world has seen, and who will get replaced slowly.
When “computers” were replaced by computers, there was a division of labour. The computation part of computers got automated while the thinking part of computation didn’t. It slowly migrated into the methods we had of creating and applying algorithms to help understand the world.
Similarly when analysts will get replaced by “analysts”, there will be a division of labour. A trend towards shifting of responsibilities will start, inside and outside the company. Every analyst I know thinks of chunks of their job as “bullshit work”, and this will get automated even as the boundaries expand.
Maybe its a job that requires starting a company. Or a new Homebrew Analyst Club to experiment with and develop this tech.
Who’s game?


If you liked this essay, you might also like:

The fight here reminds me a little of the old chip wars. Intel 4004 started its life trying to be the MOS silicon gate technology king, ready to calculate. Pretty soon the market had multiple specialised processors for specific tasks, which got slowly whittled away as the general purpose processors got better and better.
You had Digital Signal Processors, specialised to efficiently process audio and video in real time. You had Field Programmable Gate Arrays, used in aerospace and defense etc. You had Floating Point Arrays, designed to perform high speed floating point arithmetic, or Network Processors, designed to do its eponymous tasks.
And there were companies built on the back of this. Xilinx for FPGAs, or Altera. Analog Devices for DSP chips. Altera was bought by Intel for $16 billion, and AMD acquired Xilinx for $35 billion.
It’s somewhat analogous to the AI world. We have foundational models like GPT-3 being built by startups now large enough to be incumbents, and we have people trying to create their own or compete against these general-purpose processors.
Fuzzy processors are particularly skilful here. They’re built off of generative AI, which are anything from anything machines, and they have some version of an internal world model inside them. So they tend to produce relatively coherent but non deterministic answers to a substantial variety of human questions. Like a calculator works because the idea of arithmetic operations “makes sense” to it, LLMs can “make sense” of words, just to a fuzzier degree.
But both because the AI itself has been getting better, and because LLMs offer a new processor, we can now do more.
As a friend pointed out, this might hold better for chiplets than processors, but I like the sound of processors better as an analogy
I also did this for my profile, from linkedin and www.strangeloopcanon.com and twitter, and it did pretty well in figuring out what I thought about talent and startups and AI. As the types of information you can throw at LLMs grow, we also get to use these processors in ways we’ve not thought of!
For travel this might mean extracting specific info on Places, Times or Travel, and creating alternate search options. Which means you can test a few options against each other, I'd you wanted to (simultaneous check of the travel you wanted, and it's opposite, or its companion searches).

Now, you can, should you want to, add another LLM to choose from amongst the searches, optimized for whatever you like.

Isn't this pretty incredible?
The hardest part of the whole thing (for me) was to take arbitrarily formatted documents and getting the text from it without completely messing things up. But when you do, you can even get it to output tables!
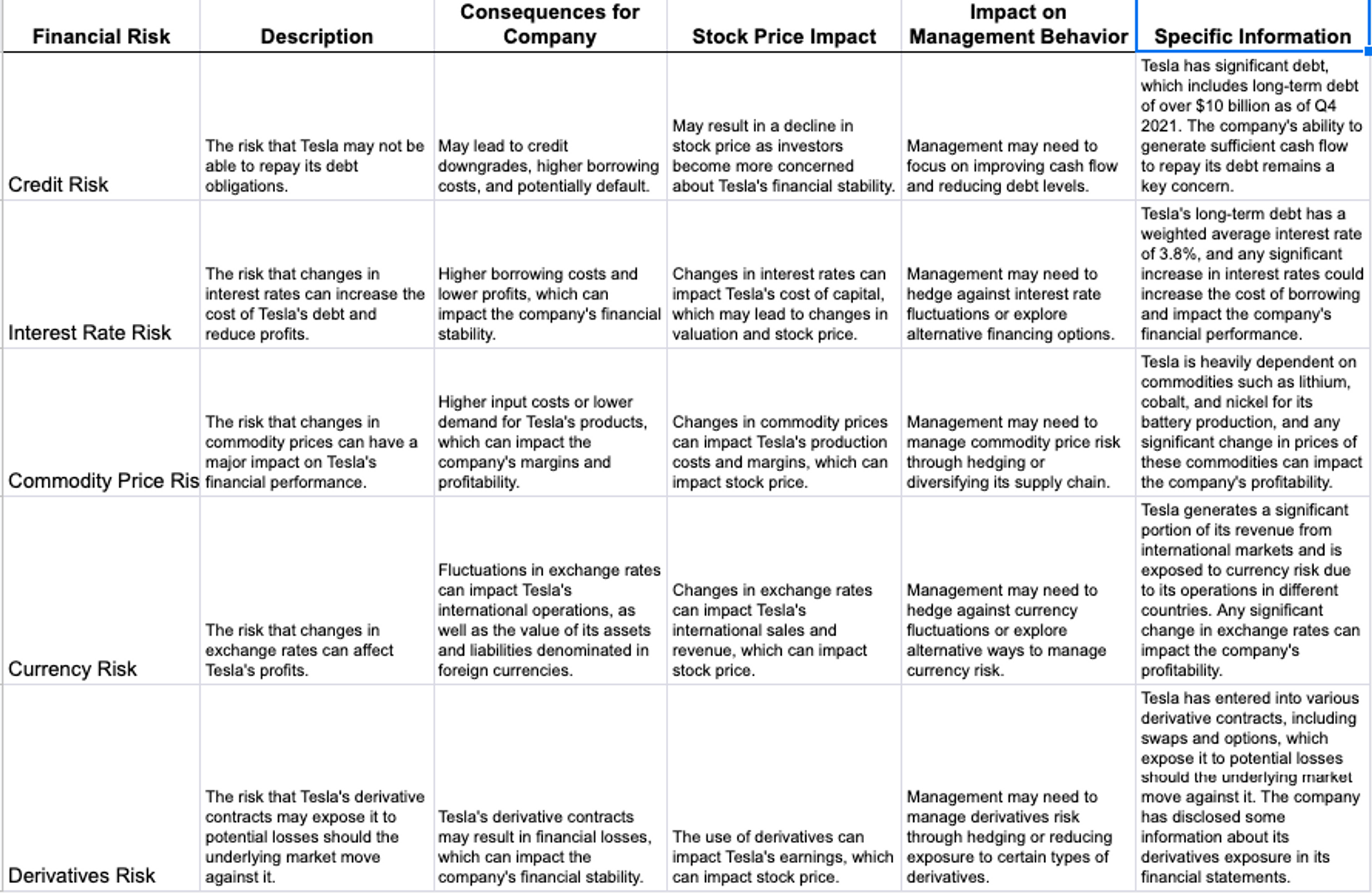
The next extrapolation was for me is to try and figure out how these can be linked together. Both the Q&A and summaries are (perhaps necessarily) a little anodyne, but I found this fixable through better prompting, or even prompting repeatedly after the fact.
When primed on being the type of person who reads Strange Loop Canon, and if you input the essays and ask about talent selection problems, we get this.
For instance, with the previous Tesla question, after indexing a bunch of annual reports, I wanted to to use it to do various calculations, like measure things like computing particular risk metrics. But Wolfram Alpha requires much more specific inputs, so I had to train GPT-3 on how to make those.
Thanks Rohit, interesting project!
Do you have anything written about the negative impact to the economy in the form of job loss? If not, do you mind sharing your opinion on this?
Thanks, very insightful.