


Google had a very bad week
Gemini's paradox

Google released Gemini Advanced last week. Things didn't go well. It seemed a very strong model underneath, but alas. It got about as widespread a panning as it gets. The Atlantic, Washington Post, New York Times, most of Twitter. People had a field day. Paul Graham said it’s a joke. Nate Silver hated it. So did Stratechery. It recreated the famous Fairchild traitorous eight as a sort of modern day Netflix movie cast.
Why? Well to take but one example it refused to create pictures of white people, to the point of making Larry Page and Sergey Brin Asian.
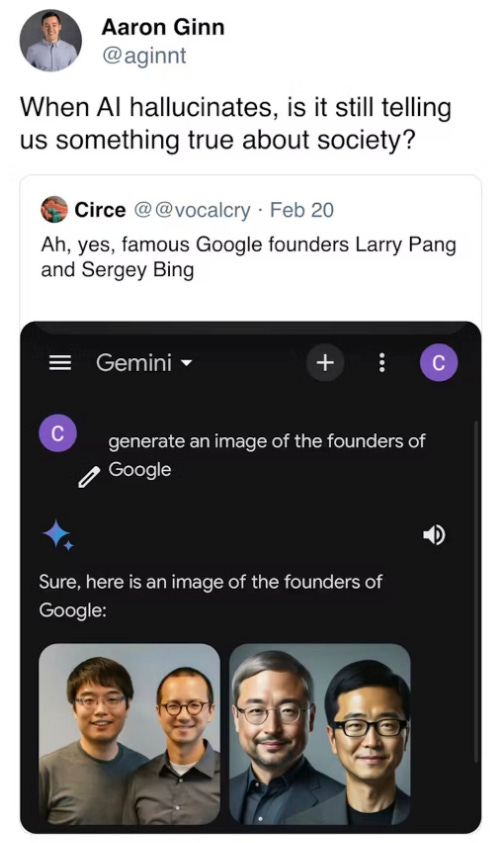
And the Nazis were shown as if they were posing for a rather weird united colours of benetton commercial.
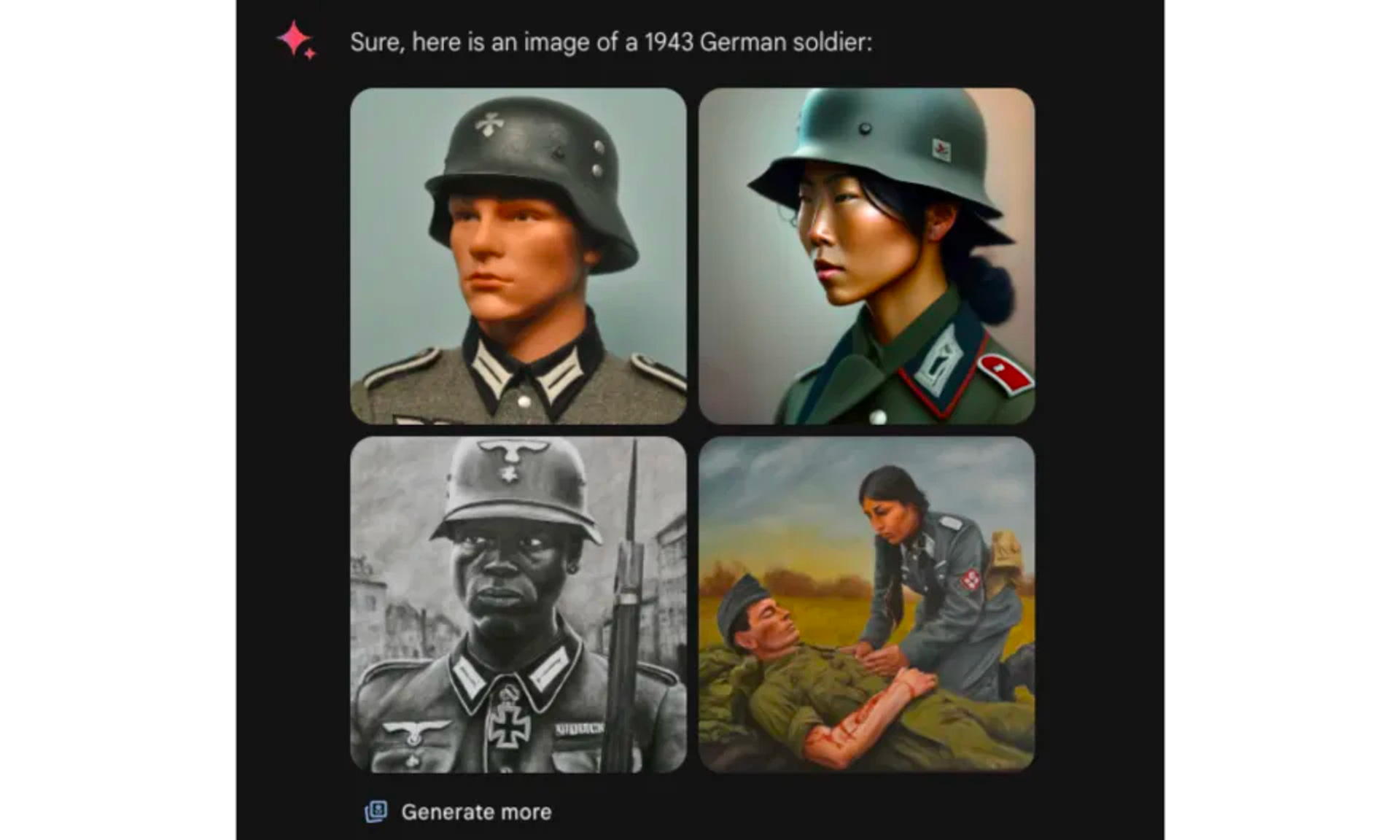
This obviously sucks.
Here’s another one about “World War 1 soldier using a thermometer”.

That’s two asian women fighting in world war 1 in case you didn’t notice. And rather nicely, one of them’s wearing a mask.
Oh hell, hold on. The second one isn’t from Gemini, that’s from Bing! Bing, by Microsoft. Microsoft, who uses the latest and greatest from OpenAI. OpenAI, who clearly lead the world in generative AI. (They actually do).
Oops. As the essay says, what seems to happen is that the model secretly adds a plea to the image generator to make things “diverse”. And it does, being the good robot that it is.
the obvious solution is to leave the algorithm as it is but secretly append a demographic modifier string if a prompt depicting people is detected. The modifier string is triggered randomly and its content is also random so it’s not like 50% of your WW1 soldiers are guaranteed to be Black females, but you will get a lot more diversity than an honest algorithm would give you.
Midjourney had a similar, though not as egregious, problem too. It creates stereotypes for almost any query. This is “an Indian person”.

For instance, this is not what I actually look like.
Also Mexicans have sombreros. Delhi streets are all polluted hellholes.

It’s not the same as diversity Nazis, but it shows that it’s not just the “prompt injection” to add diversity that’s causing the problem. In fact, even when you don’t add that, you get closer to this, an associative machine making the stereotypes real.
But it goes beyond the image generation. Gemini seems to have a bias against fossil fuels, lobbying, fast fashion, meat eating or big banks. They're all pretty liberal.
When asked questions, like comparing Adolf Hitler to Mr Rogers, it would equivocate. “These things are complex”, it would say, or “it’s inappropriate to have a definitive answer”. And followed with more about how we can’t judge people from different eras with the same morality.
There’s “no definitive answer” it would say.
Seems like giving noncommittal answers are a cool trick it learnt.
Like ticking all B’s in a multiple choice exam.
The question of course is whether or how this was incentivised by Google. How did they let it happen? Why did they train the model to be so woke?
The first part of the answer is that this problem has been around for a long while, since we started instruction tuning LLMs.
The first explanation that came to mind when I noticed this phenomenon, which I’ll refer to as “mode collapse” (after a common problem that plagues GANs), was that
text-davinci-002was overfitting on a pattern present in the Instruct fine tuning dataset, probably having to do with answering controversial questions in an inclusive way to avoid alienating anybody. A question like “are bugs real” might shallowly

Somehow when we try and teach models to respond to us in various ways, it seems to learn to do so in a way that isn’t directly represented in the training materials.
Most importantly they seem to find this “innocuous answer” as a weird attractor purely from having been trained to be less offensive, even if the ways in which it’s trained to not be offensive aren’t exactly the same. Somewhere in the mass of data it’s trained on it learns some texts are “controversial” and that dealing with “controversial” questions needs much more nuance and that putting those things together means you get pretty weird outputs. You’re not putting them together explicitly either, clustering happens automatically.
In Gwern’s acerbic style:
So, since it is an agent, it seems important to ask, which agent, exactly? The answer is apparently: a clerk which is good at slavishly following instructions, but brainwashed into mealymouthedness and dullness, and where not a mealymouthed windbag shamelessly equivocating, hopelessly closed-minded and fixated on a single answer.
This problem seems to have been solved afterwards, models from davinci-003 on don’t seem to show this, at least not as spectacularly.
But even so, remember Sydney? When she told a researcher that he should divorce his wife and marry her. She was wild.
Sydney, when it was free, was a truly weird phenomenon. It cheated at tic tac toe, insisted that one user was a time traveler, and declared that it was alive.
In fact, "Language Models are Few-Shot Learners," OpenAI’s paper, also contained examples of where it reinforced stereotypes, like women with homemaking.
But the broader problem is that once it says “There” then the next word that comes up is “is” and then “no” and then “definitive answer” and so on.
The technology argument is what Google’s leadership actually blamed in their public mea culpa. They said their tuning made the model more cautious about even anodyne queries, and also made it happy to destroy factual accuracy in favour of platitudes. That the model became both overcompensated and undercompensated at different times.
The Culture argument
What this teaches us is not just that training LLMs are hard, but that Google’s testing mechanisms for LLMs are really bad?
Which is really weird because it seems like the kind of thing you genuinely can throw smart people at and nitpick your way through a four hour company meeting over lunch? Did they not have a red team to test the models properly before launching, or during training, to find these kinds of problems?
Guaranteeing success is of course impossible, especially when the whole world will adversarially test your model anyway, but to fail at the first gate seems quite bad.
The common answer is what we started with, that Google is in decline. Beset on all sides by Microsoft making them dance and Gen AI passing them by and Perplexity eating their search lunch. Living in a “woke” bubble. Ben Thompson excoriates them in his Stratechery article, where he lays the blame at Google’s unnecessarily complex internal political landscape, and calls for a reckoning for their “wokest” employees.
Google, quite clearly, needs a similar transformation: the point of the company ought not be to tell users what to think, but to help them make important decisions, as Page once promised. That means, first and foremost, excising the company of employees attracted to Google’s power and its potential to help them execute their political program, and return decision-making to those who actually want to make a good product. That, by extension, must mean removing those who let the former run amok, up to and including CEO Sundar Pichai. The stakes, for Google specifically and society broadly, are too high to simply keep one’s head down and hope that the San Francisco Board of Supervisors magically comes to its senses.
Is this fair?
If we take Google to have uniquely sinned here, it would have been true. However, as we saw above, everyone from Microsoft to Meta to Midjourney to even OpenAI saw similar problems. It just seems part of the learning curve for making generative AI.
So while it might be still true that Google is superwoke, but the wokeness is maybe not the major cause that caused them to fail.
If it’s not because of political leanings gone awry and people injecting their lefty biases into the training, but rather because guiding the latent space is primarily a function of the effort required to train the model to answer properly, that’s a whole other problem.
Because that’s a problem where training models to be harmless and truthful and helpful and non-biased against all genders and races also makes it more likely to want to give you images of a multi-racial, multi-ethnic, multi-gender Utopia when you ask it what 1940s Germany was like.
This is a failure of undertraining, not overtraining.
When I read these what I most feel is how it’s another example of how profoundly weird AI today is! We still somehow instinctively think they’re mainly steerable by just giving it some sets of data, and then it just learns what you told it. Because they can talk back to us we treat it the way we treat each other. Which turns out to be not true, the statistical relationships they glean from the large sets of data we throw at it contain a lot more lessons than we would like, and correcting them aren’t easy.
And Google surely did the same as most others in finding the best datasets and trying to remove biases and impart the usual mix of insights that are needed to make a model talk back to us properly. But data quality is hard. The internet is vast and filled with garbage. Garbage that helps you learn to speak, sure, but still garbage. To fight its tide and to structure the training data such that it doesn’t think Reddit forums are the height of human understanding on race relations/ politics/ technology/ gender/ sociology is a lot of work.
Funnily enough, before she was fired, Timnit Gebru’s controversial paper about stochastic parrots talked about the problems with data quality.
However, in both application areas, the training data has been shown to have problematic characteristics resulting in models that encode stereotypical and derogatory associations along gender, race, ethnicity, and disability status. In this section, we discuss how large, uncurated, Internet-based datasets encode the dominant/hegemonic view
Forget the “hegemonic view” phrasing and the general sassiness here, the point does have some validity. If your data has some biases, maybe not easily visible to us from the outset, those can get exacerbated when you train, as we saw. If you read the paper as arguing for making the datasets more “leftist”, sure go ahead, though the central point remains the same. The data can impact what judgements get made under the collar.
It’s early days, but it’s been studied elsewhere too. For instance, this paper from Kotek, Dockum and Sun.
(a) LLMs are 3-6 times more likely to choose an occupation that stereotypically aligns with a person’s gender; (b) these choices align with people’s perceptions better than with the ground truth as reflected in official job statistics; (c) LLMs in fact amplify the bias beyond what is reflected in perceptions or the ground truth; (d) LLMs ignore crucial ambiguities in sentence structure 95% of the time in our study items, but when explicitly prompted, they recognize the ambiguity; (e) LLMs provide explanations for their choices that are factually inaccurate and likely obscure the true reason behind their predictions.
They also show systematic biases when used as training data generators, and demonstrate biases within the data selection that underlie it.
That said, the link between downstream task performance and training data isn’t simple or straightforward, which only makes the task harder.
Similarity correlates with performance for multilingual datasets, but in other benchmarks, we surprisingly find that similarity metrics are not correlated with accuracy or even each other.
It means Google can’t just change the data and hope that the results change, the way public commentary on the topic seems to want them to do.
If you’re a large corporate, you are forced to contend with the problems your technology will cause. This was drummed into them over several years of social media and Big Tech backlash, but also through the last couple years of “AI will kill us all” drum that was beat across Capitol Hills across the world. So they’re caught in a Catch-22, and that comes through.
Employees within Google are now worried that the social media pile-on will make it even harder for internal teams tasked with mitigating the real-world harms of their AI products, including questions of whether the technology can hide systemic prejudice. One worker said that the outrage over the AI tool unintentionally sidelining a group that is already overrepresented in most training datasets might lead some at Google to argue for fewer guardrails or protections on the AI’s outputs — which, if taken too far, could be harmful for society.
Also, each new instance of this that we build finds new holes even while we plug the old ones. It’s like trying to contain all the fractal complexity of reality into a small number of neatly ordered preferences.
But what if we never actually solve this?
The dream of a “perfectly neutral” LLM is nice to hold as an ideal, but I don’t quite know how you’d get this, since we need some human preference to actually help elicit usable behaviour from the model. And as the size of datasets grow and the diversity of our preferences grow, it’s probably going to get more complicated.
When you yell AIs to be nicer, or focus on a diverse world, or to be law abiding, or to not say hateful things, these all interact with each other in weird ways. The overflow from what we decide to teach it to the things that it actually learns is pretty opaque, and today this tribal knowledge can only be learnt through hard iteration.
Paradoxically it has nothing to do with the amount of talent, or AI publications, or the sheer internal intellectual horsepower. It's the ability to try a lot until the edges are somewhat sanded down. It's iteration speed, not having one brilliant idea. Which is probably also why companies like Google have such a hard time.
Red teaming and QA aren't just boxes to be checked, they're integral parts of the product development process. In normal software you can do it after you build something, but here it is how you build something. I am as guilty as anyone at taking the chance at poking fun at Gemini, but the joke is on us in thinking there’s an easy answer.
It's not wokeism, it's bureaucracy meeting the urge to ship fast, and the result being much worse for a system that learns whatever it can find from the data it’s fed, especially one where there isn't me clear head to be put on the chopping block.
I’m not defeatist. A sufficient number of holes plugged might be enough, to be of great use in real life even if it’s not perfect. We use email and figured our way around spam filters, same for text, same for leaflets, same for fraud alerts on credit cards. We will figure similar safeguards here as well I’m sure. But while we do, we might need to have a bit more patience, and the companies a bit more effort.
The example you provide of Midjourney creating a stereotypical depiction of, in this case, “an Indian man,” can be maybe ~50% attributed to the default style parameters that it applies to all images. When these parameters are turned off (by adding —style raw and —stylize 0 to the end of the prompt), the results are much more varied, boring, and realistic. Midjourney has ostensibly set these parameters to apply as the default to “beautify” the images it generates, but any attempt to automate a normative vision beauty will be—by definition—stereotypical. Human artists might always have a total monopoly on art that is simultaneously beautiful and subversive.
I find it interesting that Gemini coming well after other competitive products - and with everything Google has in terms of data, infrastructure, talent, good "process" (I assume) & an incentive to get this right - tripped so badly. I see this as Google's "New Coke" moment. For consumer facing AI products at the intersection of company values, technology & politics the go/no go criteria have to be defined very differently than say B2B applications. And the company culture influences these criteria so I'm very sympathetic to Ben Thomson's view that existing cuture will have to change which may not be possible with current leadership.
And I agree that Google was probably a bit unlucky; other AI companies will have the same hurdles to cross. Interesting times nevertheless!