


Is AI hitting a wall?

I'll start at the end. No. It's not.
Of course, I can’t leave it at that. The reason the question comes up is that there have been a lot of statements that they are stalling a bit. Even Ilya has said that it is.
Ilya Sutskever, co-founder of AI labs Safe Superintelligence (SSI) and OpenAI, told Reuters recently that results from scaling up pre-training - the phase of training an AI model that use s a vast amount of unlabeled data to understand language patterns and structures - have plateaued.
Also, as he said at Neurips yesterday:

Of course, he’s a competitor now to OpenAI, so maybe it makes sense to talk his book by hyping down compute as an overwhelming advantage. But still, the sentiment has been going around. Sundar Pichai thinks the low hanging fruit are gone. There’s whispers on why Orion from OpenAI was delayed and Claude 3.5 Opus is nowhere to be found.
Gary Marcus has claimed vindication. And even though that has happened before, a lot of folks are worried that this time he's actually right.
Meanwhile pretty much everyone inside the major AI labs are convinced that things are going spectacularly well and the next two years are going to be at least as insane as the last two. It’s a major disconnect in sentiment, an AI vibecession.
So what's going on?
Until now, whenever the models got better at one thing they also got better at everything else. This was seen as the way models worked, and helped us believe in the scaling thesis. From GPT-4 all the way till Claude 3.5 Sonnet we saw the same thing. And this made us trust even more in the hypothesis that when models got better at one thing they also got better at everything else. They demonstrated transfer learning and showed emergent capabilities (or not). Sure there were always those cases where you could fine tune it to get better at specific medical questions or legal questions and so on, but those also seem like low-hanging fruit that would get picked off pretty quickly.
But then it kind of started stalling, or at least not getting better with the same oomph it did at first. Scaling came from reductions in cross-entropy loss, basically the model learning what it should say next better, and that still keeps going down. But for us, as observers, this hasn’t had enough visible effects. And to this point, we still haven’t found larger models which beat GPT 4 in performance, even though we’ve learnt how to make them work much much more efficiently and hallucinate less.
What seems likely is that gains from pure scaling of pre-training seem to have stopped, which means that we have managed to incorporate as much information into the models per size as we made them bigger and threw more data at them than we have been able to in the past. This is by no means the only way we know how to make models bigger or better. This is just the easiest way. That’s what Ilya was alluding to.
We have multiple GPT-4 class models, some a bit better and some a bit worse, but none that were dramatically better the way GPT-4 was better than GPT-3.5.
The model most anticipated from OpenAI, o1, seems to perform not much better than the previous state of the art model from Anthropic, or even their own previous model, when it comes to things like coding even as it captures many people’s imagination (including mine).
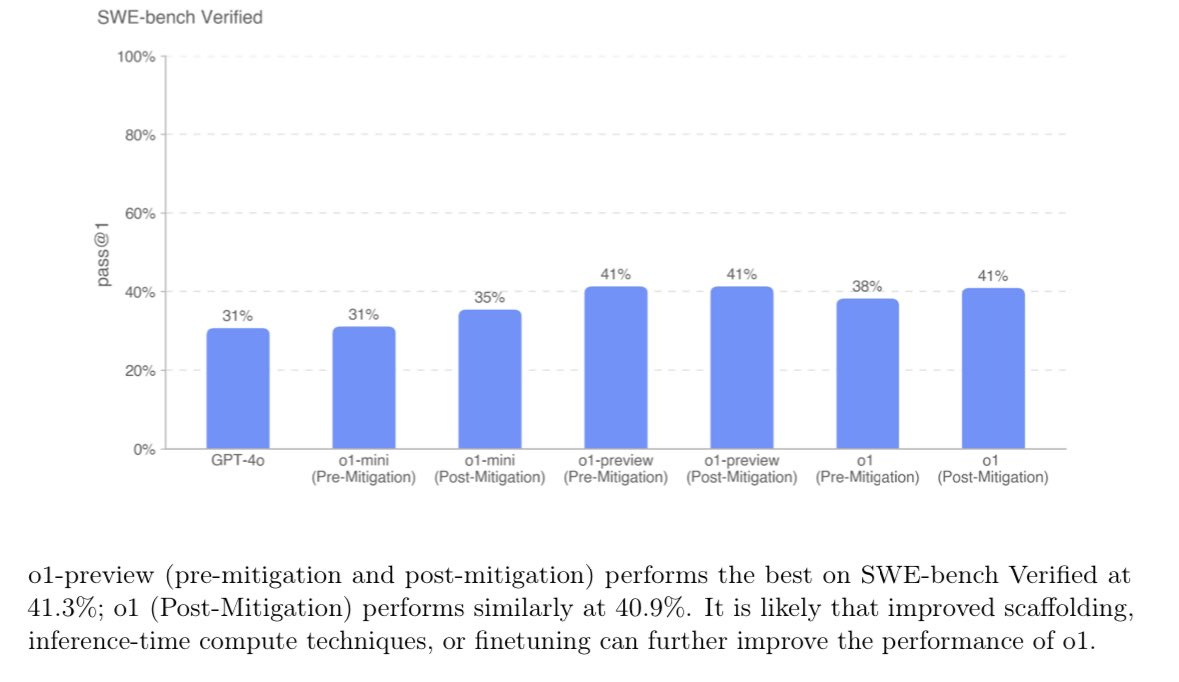
But this is also because we’re hitting against our ability to evaluate these models. o1 is much much better in legal reasoning, for instance. Harvey, the AI legal company, says so too. It also does much much better with code reviews, not just creating code. It even solves 83% of IMO math problems, vs 13% for gpt4o. All of which to say, even if it doesn’t seem better at everything against Sonnet or GPT-4o, it is definitely better in multiple areas.
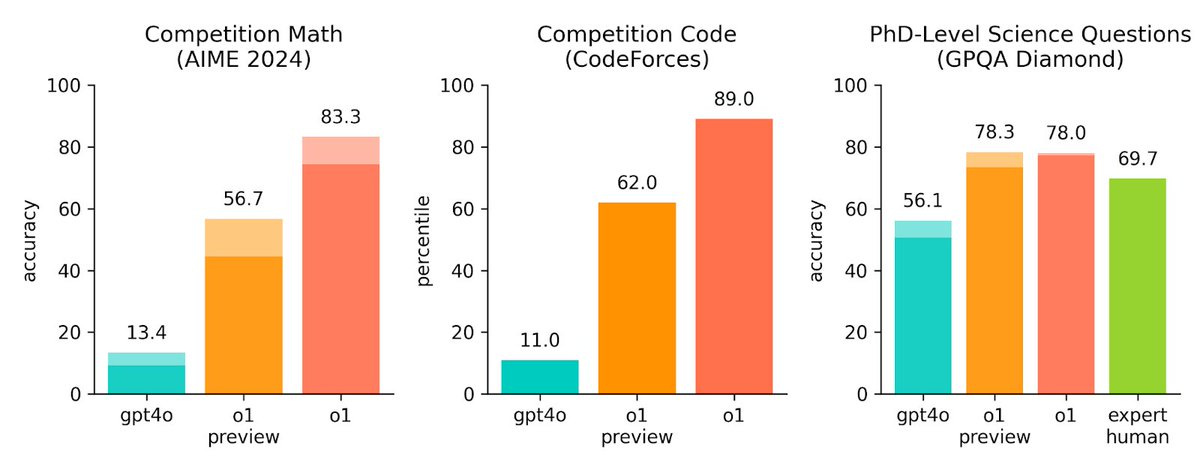
A big reason why people do think it has hit a wall is that the evals we use to measure the outcomes have saturated. I wrote as much when I dug into evals in detail.
Today we do it through various benchmarks that were set up to test them, like MMLU, BigBench, AGIEval etc. It presumes they are some combination of “somewhat human” and “somewhat software”, and therefore tests them on things similar to what a human ought to know (SAT, GRE, LSAT, logic puzzles etc) and what a software should do (recall of facts, adherence to some standards, maths etc). These are either repurposed human tests (SAT, LSAT) or tests of recall (who’s the President of Liberia), or logic puzzles (move a chicken, tiger and human across the river). Even if they can do all of these, it’s insufficient to use them for deeper work, like additive manufacturing, or financial derivative design, or drug discovery.
The gaps between the current models and AGI are: 1) they hallucinate, or confabulate, and in any long-enough chain of analysis it loses track of what its doing. This makes agents unreliable. And 2) they aren’t smart enough to create truly creative or exceptional plans. In every eval the individual tasks done can seem human level, but in any real world task they’re still pretty far behind. The gap is highly seductive because it looks small, but its like a Zeno’s paradox, it shrinks but still seems to exist.
But regardless of whether we’ve hit somewhat of a wall on pretraining, or hit a wall on our current evaluation methods, it does not mean AI progress itself has hit a wall.
So how to reconcile the disconnect? Here are three main ways that I think AI progress will continue its trajectory. One, there still remains a data and training overhang, there’s just a lot of data we haven’t used yet. Second, we’re learning to use synthetic data, unlocking a lot more capabilities on what the model can actually do from the data and models we have. And third, we’re teaching the models reasoning, to “think” for longer while answering questions, not just teach it everything it needs to know upfront.
We can still scale data and compute
The first is that there is still a large chunk of data that’s still not used in training. There's also the worry that we've run out of data. Ilya talks about data as fossil fuels, a finite and exhaustible source.
But they might well be like fossil fuels, where we identify more as we start to really look for them. The amount of oil that’s available at $100 a barrel is much more than the amount of oil that’s available at $20 a barrel.
Even in the larger model runs, they don't contain a large chunk of data we normally see around us. Twitter, for the most famous one. But also, a large part of our conversations. The process data on how we learn things, or do things, from academia to business to sitting back and writing essays. Data on how we move around the world. Video data from CCTVs around the world. Temporal structured data. Data across a vast range of modalities, yes even with the current training of multimodal models, remains to be unearthed. Three dimensional world data. Scientific research data. Video game playing data. An entire world or more still lay out there to be mined!
There's also data that doesn't exist, but we're creating.
https://x.com/watneyrobotics/status/1861170411788226948?t=s78dy7zb9mlCiJshBomOsw&s=19

And in creating it we will soon reach a point of extreme dependency the same way we did for self-driving. Except that because folding laundry is usually not deadly it will be even faster in getting adoption. And there are no “laundry heads” like gear heads to fight against it. This is what almost all robotics companies are actually doing. It is cheaper to create the data by outsourcing the performance of tasks through tactile enough robots!
With all this we should imagine that the largest multimodal models will get much (much) better than what they are today. And even if you don’t fully believe in transfer learning you should imagine that the models will get much better at having quasi “world models” inside them, enough to improve their performance quite dramatically.
Speaking of which…
We are making better data
And then there's synthetic data. This especially confuses people, because they rightly wonder how you can use the same data in training again and make it better. Isn’t that just empty calories? It’s not just a bad question. In the AI world this would be restated as “it doesn’t add ton of new entropy to original pre-training data”, but it means the same thing.
The answer is no, for (at least) three separate reasons.
We already train using the raw data we have multiple times to learn better. The high quality data sets, like Wikipedia, or textbooks, or Github code, are not used once and discarded during training. They’re used multiple times to extract the most insight from it. This shouldn't surprise us, after all we and learn through repetition, and models are not so different.
We can convert the data that we have into different formats in order to extract the most from it. Humans learn from seeing the same data in a lot of different ways. We read multiple textbooks, we create tests for ourselves, and we learn the material better. There are people who read a mathematics textbook and barely pass high school, and there’s Ramanujan.
So you turn the data into all sorts of question and answer formats, graphs, tables, images, god forbid podcasts, combine with other sources and augment them, you can create a formidable dataset with this, and not just for pretraining but across the training spectrum, especially with a frontier model or inference time scaling (using the existing models to think for longer and generating better data).We also create data and test their efficacy against the real world. Grading an essay is an art form at some point, knowing if a piece of code runs is not. This is especially important if you want to do reinforcement learning, because “ground truth” is important, and its easier to analsye for topics where it’s codifiable. OpenAI thinks it’s even possible for spaces like law, and I see no reason to doubt them.
There are papers exploring all the various ways in which synthetic data could be generated and used. But especially for things like enhancing coding performance, or enhanced mathematical reasoning, or generating better reasoning capabilities in general, synthetic data is extremely useful. You can generate variations on problems and have the models answer them, filling diversity gaps, try the answers against a real world scenario (like running the code it generated and capturing the error message) and incorporate that entire process into training, to make the models better.
If you add these up, this was what caused excitement over the past year or so and made folks inside the labs more confident that they could make the models work better. Because it’s a way to extract insight from our existing sources of data and teach the models to answer the questions we give it better. It’s a way to force us to become better teachers, in order to turn the models into better students.
Obviously it’s not a panacea, like everything else this is not a free lunch.

The utility of synthetic data is not that it, and it alone, will help us scale the AGI mountain, but that it will help us move forward to building better and better models.
We are exploring new S curves
Ilya’s statement is that there are new mountains to climb, and new scaling laws to discover. “What to scale” is the new question, which means there are all the new S curves in front of us to climb. There are many discussions about what it might be - whether it’s search or RL or evolutionary algos or a mixture or something else entirely.
o1 and its ilk is one answer to this, but by no means the only answer. The Achilles heel of current models is that they are really bad at iterative reasoning. To think through something, and every now and then to come back and try something else. Right now we do this in hard mode, token by token, rather than the right way, in concept space. But this doesn’t mean the method won’t (or can’t) work. Just that like everything else in AI the amount of compute it takes to make it work is nowhere close to the optimal amount.
We have just started teaching reasoning, and to think through questions iteratively at inference time, rather than just at training time. There are still questions about exactly how it’s done: whether it’s for the QwQ model or Deepseek r1 model from China. Is it chain of thought? Is it search? Is it trained via RL? The exact recipe is not known, but the output is.
And the output is good! Here in fact is the strongest bearish take on it, which is credible. It states that because it’s trained with RL to “think for longer”, and it can only be trained to do so on well defined domains like maths or code, or where chain of thought can be more helpful and there’s clear ground truth correct answers, it won’t get much better at other real world answers. Which is most of them.
But turns out that’s not true! It doesn't seem to be that much better at coding compared to Sonnet or even its predecessors. It’s better, but not that much better. It's also not that much better at things like writing.
But what it indisputably is better at are questions that require clear reasoning. And the vibes there are great! It can solve PhD problems across a dizzying array of fields. Whether it’s writing position papers, or analysing math problems, or writing economics essays, or even answering NYT Sudoku questions, it’s really really good. Apparently it can even come up with novel ideas for cancer therapy.
https://x.com/DeryaTR_/status/1865111388374601806?t=lGq9Ny1KbgBSQK_PPUyWHw&s=19

This is a model made for expert level work. It doesn’t really matter that the benchmarks can’t capture how good it is. Many say its best to think of it as the new “GPT 2 moment” for AI.
What this paradoxically might show is benchmark saturation. We are no longer able to measure performance of top-tier models without user vibes. Here’s an example, people unfamiliar with cutting edge physics convince themselves that o1 can solve quantum physics which turns out to be wrong. And vibes will tell us which model to use, for what objective, and when! We have to twist ourselves into pretzels to figure out which models to use for what.
https://x.com/scaling01/status/1865230213749117309?t=4bFOt7mYRUXBDH-cXPQszQ&s=19
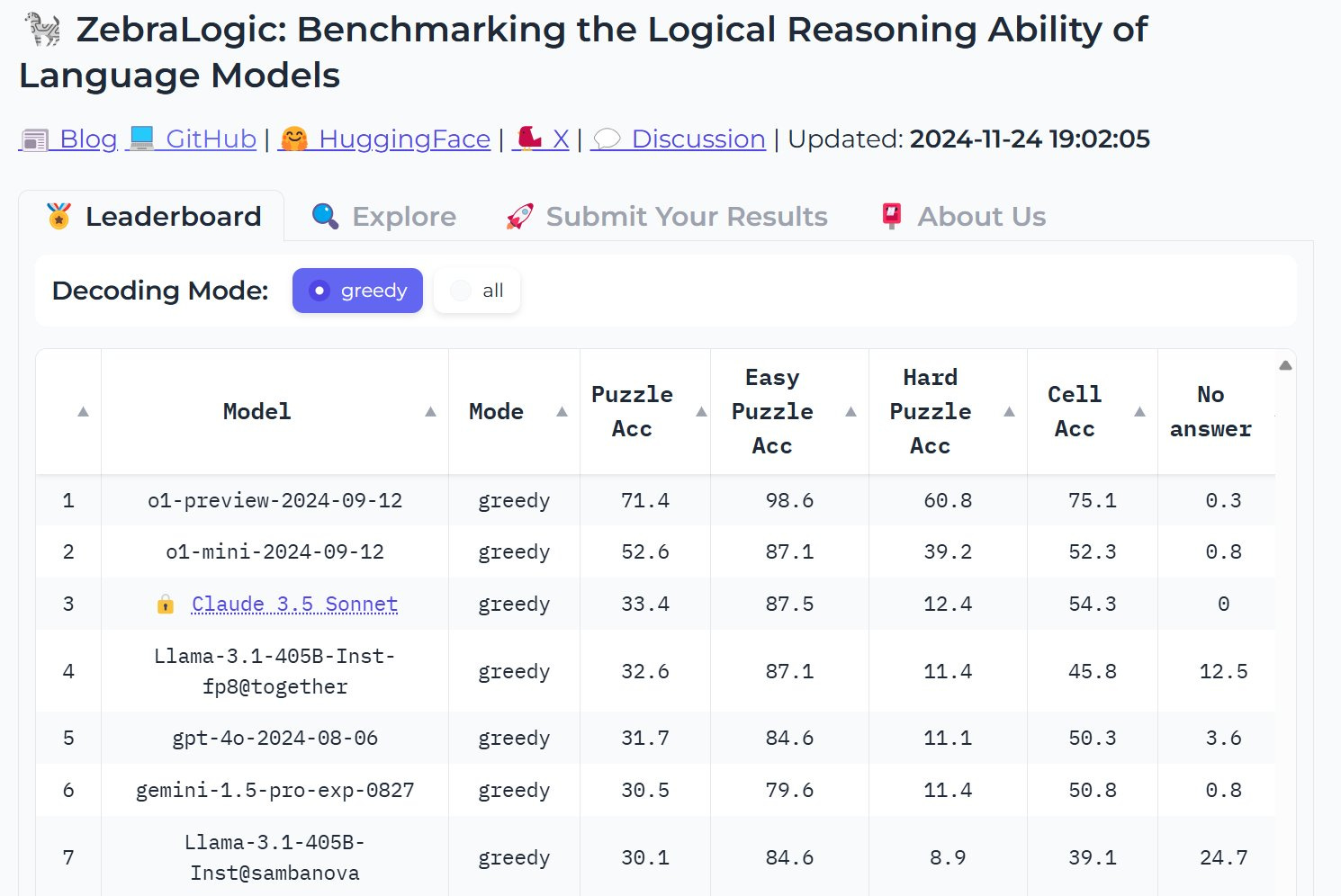
This is the other half of the Bitter Lesson that we had ignored until recently. The ability to think through solutions and search a larger possibility space and backtrack where needed to retry.
But it will create a world where scientists and engineers and leaders working on the most important or hardest problems in the world can now tackle them with abandon. It barely hallucinates. It actually writes really impressive answers to highly technical policy or economic questions. It answers medical questions with reasoning, including some tricky differential diagnosis questions. It debugs complex code better.
It’s nowhere close to infallible, but it’s an extremely powerful catalyst for anyone doing expert level work across a dizzying array of domains. And this is not even mentioning the work within Deepmind of creating the Alpha model series and trying to incorporate those into the Large Language world. There is a highly fertile research ecosystem desperately trying to build AGI.

We’re making the world legible to the models just as we’re making the model more aware of the world. It can be easy to forget that these models learn about the world seeing nothing but tokens, vectors that represent fractions of a world they have never actually seen or experienced. We’re working also on making the world legible to these models! And it’s hard, because the real world is annoyingly complicated.
We have these models which can control computers now, write code, and surf the web, which means they can interact with anything that is digital, assuming there’s a good interface. Anthropic has released the first salvo by creating a protocol to connect AI assistants to where the data lives. What this means is that if you want to connect your biology lab to a large language model, that's now more feasible.
Together, what all this means is that we are nowhere close to AI itself hitting a wall. We have more data that remains to be incorporated to train the models to perform better across a variety of modalities, we have better data that can teach particular lessons in areas that are most important for them to learn, and we have new paradigms that can unlock expert performance by making it so that the models can “think for longer”.
Will this result in next generation models that are autonomous like cats or perfectly functional like Data? No. Or at least it’s unclear but signs point to no. But we have the first models which can credibly speed up science. Not in the naive “please prove the Riemann hypothesis” way, but enough to run data analysis on its own to identify novel patterns or come up with new hypotheses or debug your thinking or read literature to answer specific questions and so many more of the pieces of work that every scientist has to do daily if not hourly! And if all this was the way AI was meant to look when it hit a wall that would be a very narrow and pedantic definition indeed.
imo the ones who think ai is stalling are those who are too unimaginative to think up novel frameworks/applications. with current LLMs we can already automate the vast majority of the annoying processes that plague our minds in corpo jobs but we just dont yet have the integrations.
in a lot of cases where ppl are mad that AI cant solve their problems they are primarily mad that AI can't understand what they are saying/asking for because they themselves haven't articulated it well enough or broken it down well enough.
Hi Rohit – This certainly isn’t my domain, so feel free to ignore this comment if it’s dumb. Perhaps it is.
But when I think of “innovation”, I sort of think of it in two categories. The first is just applying newly discovered techniques to areas that have not yet benefited from those new methods. To me, your “More Data” and “Synthetic Data” fall into this category. It’s really just applying more money and time to techniques we’re pretty sure will work.
But the “S-Curve” thing… which I think amounts to just new inventions… that seems to be a different matter. Doesn’t that rely on someone inventing a new technique?
When I listen to the Silicon Valley experts on the All-in Podcast, for example, they all seem so utterly certain that AI will reach new heights in the years to come. I agree, if you think of those heights in terms of your “More Data” and “Synthetic Data”. But on the other hand, when it comes to new algorithmic innovations, you just never know if that will happen or not until someone actually does it.
Geez… not only do the Silicon Valley types seem certain total AGI is going to happen, but they actually put short term time tables on it. Didn’t Marc Andreesen say it would be in two more years? How do you know when someone is going to invent something? Will quantum computers ever be able to isolate particles from nature efficiently enough to have lots of qubits? Will fusion energy ever happen? Will someone invent antigravity boots? You just don’t know until someone actually does it.
So the confidence that Silicon Valley has in AGI baffles me a bit. I’m definitely a believer in applying existing techniques to new domains, of course. But I’m not at all confident that someone will invent something that hasn’t been invented yet. And certainly not when that invention will occur.
You do make a good case though, for there being many lines of attack... lots of ways that innovation might take place. That certainly does make me think the odds of innovation do seem pretty good. I wish I could be confident that was a good thing though, as I'm not sure what the human spirit will be when intellectual capital is worth nothing.
Admittedly, this comment might not age well at all! :)