
LLMs breach a threshold
Open Source models get more powerful, and an AI system scores silver in Maths Olympiad

Let’s start with some history. The Arms Export Control Act of 1976, signed by Gerald Ford, high performance computing systems were placed on United States Munitions List. They were under export controls.
Here’s a list. The threshold then was 1 gigaflop of computing power. For context, your iPhone has a 1000 gigaflops.

In a similar vein cryptographic techniques were also seen as munitions, because it was so core to national security. The implication:
In the 1990s, after a report from RSA Data Security, Inc., who were in a licensing dispute with regard to use of the RSA algorithm in PGP, the Customs Service started a criminal investigation of Phil Zimmermann, for allegedly violating the Arms Export Control Act. The US Government had long regarded cryptographic software as a munition, and thus subject to arms trafficking export controls. At that time, the boundary between permitted ("low-strength") cryptography and impermissible ("high-strength") cryptography placed PGP well on the too-strong-to-export side (this boundary has since been relaxed). The investigation lasted three years, but was finally dropped without filing charges.
That computational threshold lasted until 2000, until when Apple computers were still considered as having weapons-grade computational power. Steve Jobs spun it as:
The Power Mac G4 is so fast that it is classified as a supercomputer by the U.S. government, and we are prohibited from exporting it to over 50 nations worldwide
I wonder at the implications of this, and what might have been a possible counterfactual:
The focus on making much of cryptography sit behind these regulations probably weakened the adoption of cryptographic tech, like adoption of SSL or HTTPS
Technological advancement was throttled, since there was limited competition in this arena, causing lags in climate modelling, genomics, even AI
Countries ended up developing their own supercomputers, like Tianhe-2 in China, as domestic development was seen as necessary for survival
US continued its technological dominance trajectory for a bit longer?
There is ENFORCE Act, being discussed, that would give permission, and allow the Commerce Department to place export controls on frontier models if they chose to. Just the way it was done for the Power Mac before. And to similarly perverse ends.
The reason this is useful to remember is that we have multiple bills, across EU, US Federal level, and California, where the focus is on a FLOPs limit, the amount of training a model has gone through, to put it under stringent regulations and reporting burden.
And one particularly timely reminder from this story is that using FLOPs as a threshold probably isn’t a good idea.
And there were two major developments in that domain this past week, which reinforce that point.
First is regarding open sourcing powerful models. A particular big worry on the regulatory about this has been that these models will get so unbelievably powerful that they become actually akin to munitions. Ones which can, autonomously if need be, guide missiles or hack computer systems or help create bombs or even cause pandemics.
It felt for a minute that the breakneck speed of AI development was coming to the top of an S curve. GPT-4 was released a year ago, an eternity in AI, and Claude 3.5 Sonnet only met its abilities, but was released recently.

And then we had Meta and Mistral drop GPT-4 class models which are both open source.
Llama 3.1 had 405B parameters, despite its continuing adherence to the trend of terrible names for AI models, was trained on 3.8*10^25 FLOPs, 3x over the limit set by EU, and 0.3x Biden’s executive order and skirting with California’s new proposed SB 1047 legislation.
Moreover, from people using it, Llama 3.1 is definitely comparable to Claude 3.5 Sonnet and GPT-4o. It doesn’t beat them in every case, neither does it lose in every case, but it’s definitely on the same level. Mistral seems similar.
Mark Zuckerberg wrote about the release:
Today, several tech companies are developing leading closed models. But open source is quickly closing the gap. Last year, Llama 2 was only comparable to an older generation of models behind the frontier. This year, Llama 3 is competitive with the most advanced models and leading in some areas. Starting next year, we expect future Llama models to become the most advanced in the industry.
This again brings to fore the same question, of the inadequacies of FLOPs based regulation. This model is the first that lay beyond the level treated as having a “systemic risk” by the European Union. It is close to the point where it breaches that threshold for US Executive Order.
Meta did plenty of safety testing the whole they released the weights.
And yet, what actually has changed?
Quantitative analysis of these results of this study show no significant uplift in performance related to usage of the Llama 3 model.
The point is not that these LLMs are definitively harmless. After all if we think they are the next General Purpose Technology they can’t be harmless. It is that the benefits outweigh the costs, and we shouldn’t cut the tech tree off at its root just because we’re afraid.
The paper even complains about the problems, from hallucinations to reliability issues.
And even as these problems remain, but we’re making progress towards better AI systems, which can do remarkable things.
As far as anyone has dug into it, the 10^26 FLOPs number came from this paper, though many numbers have been discussed generally online. The footnote points to an Our World In Data source, which itself comes from this google doc put together by Epoch, who made the chart above.

In other words, the limit was set as “slightly higher than where we seem to be”, which is a terrible way to set a regulatory limit. As Helen Toner, previous board member at OpenAI said:
A distinction that keeps getting missed:
The 10^26 threshold makes no sense as a cutoff for "extremely risky AI models."
But it does make fairly good sense as a way to identify "models beyond the current cutting edge," and at this point it seems reasonable to want
But this feels quite arbitrary, because it is!
The EU AI Act explicitly says:
A general-purpose AI model shall be presumed to have high impact capabilities pursuant to paragraph 1, point (a), when the cumulative amount of computation used for its training measured in floating point operations is greater than 10(^25)
The word “presumed” is the key part there. The presumption is that anything above 10^25 has high impact capabilities.
Look at the chart above, and tell me if this makes any sense whatsoever!
If all of this isn’t sufficient, here’s what was previously asked for. Not a long time ago, this was 2023.

Note that this would have put every LLM that you think of as completely inadequate under the same umbrella. Imagine not being able to develop GPT-3 or slowing that down for no actual reason beyond fear. As FDR said, and we should heed, “the only thing we have to fear is fear itself.”
It’s one thing if it was meant to purely trigger some soft reporting requirements, as the original intent seemed to have been. Even for the Executive Order.
But as was completely foreseeable, and was foreseen, it is being codified into actual regulations like the AI Act or SB1047.
This, if you’re focusing on creating laws that trigger jailtime for developers, needs to have a better justification than a footnote in a paper that references a google doc that one organisation put together. It’s arguably far worse than the Gigaflop requirement that made Power Macs a munition.
And there’s a second update. LLMs are not the only type of AI systems out there. More and more we’re going to see complex AI systems that combine multiple abilities. In this vein, Deepmind created an elite mathematician combining the language models it had in Gemini, AlphaGeometry, a neurosymbolic hybrid system which combines Gemini and synthetic data, and AlphaProof.

The coolest part of this, in my opinion is this:
In contrast, natural language based approaches can hallucinate plausible but incorrect intermediate reasoning steps and solutions, despite having access to orders of magnitudes more data. We established a bridge between these two complementary spheres by fine-tuning a Gemini model to automatically translate natural language problem statements into formal statements, creating a large library of formal problems of varying difficulty.
When presented with a problem, AlphaProof generates solution candidates and then proves or disproves them by searching over possible proof steps in Lean. Each proof that was found and verified is used to reinforce AlphaProof’s language model, enhancing its ability to solve subsequent, more challenging problems.
We all know that LLMs can hallucinate answers. We also know that Reinforcement Learning based AI, like AlphaGo, work best in domains which are rigorously specified, like playing Chess or Go.
What’s interesting here is that the researchers figured out a way to formalise mathematical problems such that it could be used for training the model. Because formal problems are things you can apply reinforcement learning to, and informal natural language statements are ones which we can convert to formal problems.
And it’s also important, because as Karpathy says:
Therefore, the models have to first get larger before they can get smaller, because we need their (automated) help to refactor and mold the training data into ideal, synthetic formats.
Most importantly, this move by AlphaProof shows a major problem in the discussions regarding LLMs like GPT-5 and regulatory thresholds. What we mean by AI changes constantly.
AI as used by Google to do search rankings and Meta to reorder its friend feed is different to generative AI like GPT or Gemini, and is different again to AlphaGo and its ilk, and different yet again to AlphaProof.
What they built is neurosymbolic AI, though the name itself doesn’t really help us understand it any better. Which lessons you learnt from LLM capabilities carry through to AlphaGo? And from both to AlphaProof?
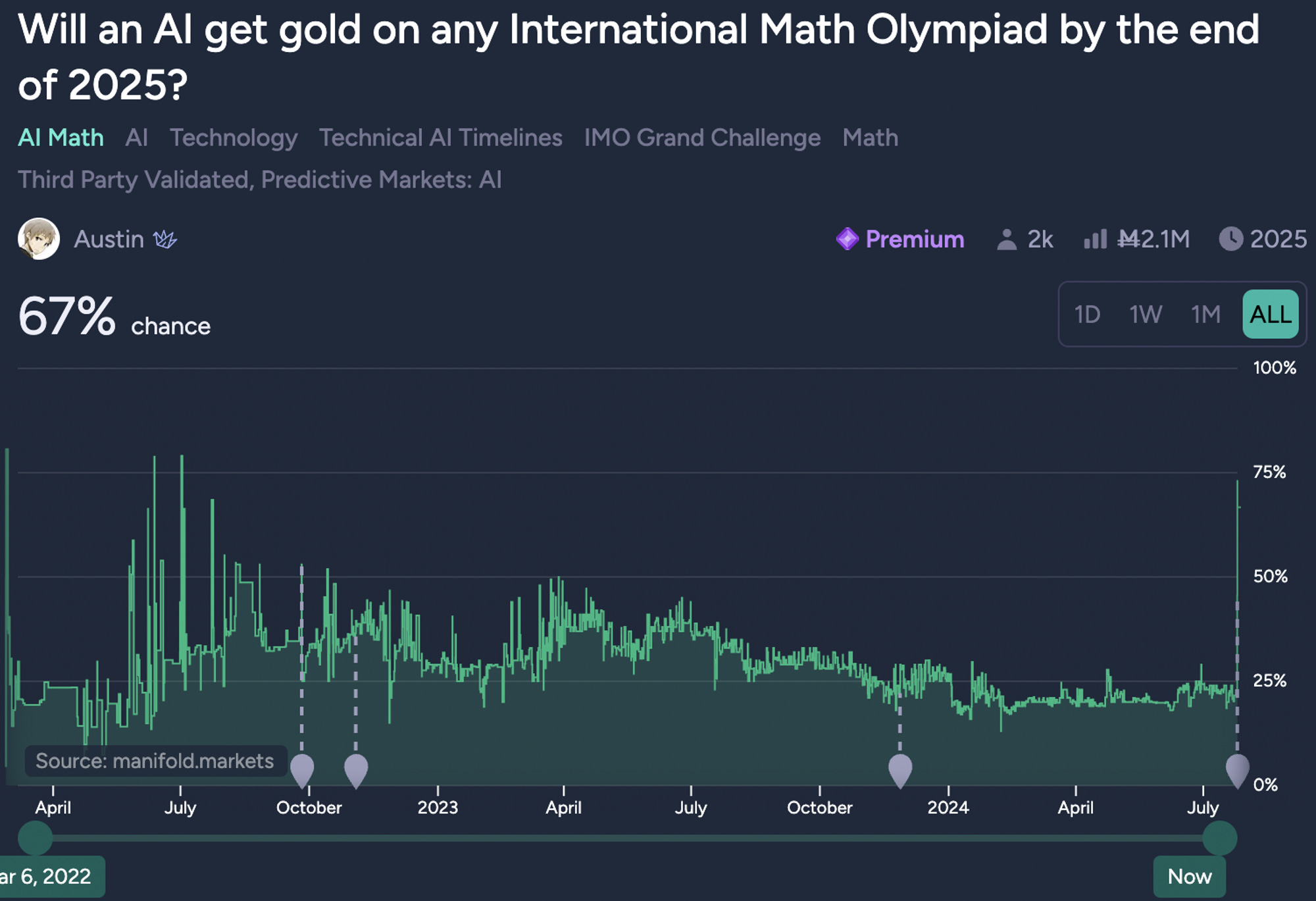
The biggest question now is, what next?
If we can convert the messiness of any sector of the world into better formalisations, then we could perhaps train a model on it. It’s not pure self play the way AlphaGo taught itself to play superhuman Go, but it’s also not entirely at the whim of teaching maths through multiple maths examples. That’s perhaps one lesson here. As we codify more aspects of our lives in a formal way the models can be taught to be better.
It worked for games, and now it worked for maths. I bet it will apply to more domains as we learn to specify them in a form that’s well suited to self-play. Coding is a strong contender.
We live in interesting times.
People with no sense of trend or trajectory whatsoever: “I think we’ve plateaued.”
Really appreciated the historical backstory here! You're consistently the most informed, sane and lucid thinker I read on all of these issues and this was no exception.