
No, LLMs are not "scheming"

For a long time people were convinced that if there was a machine that you could have a conversation with, it would be intelligent. And yet, in 2024, it no longer feels weird that we can talk to AI. We handily, demonstrably, utterly destroyed the Turing test. It’s a monumental step. And we seem to have just taken it in stride.
As I write this I have Gemini watching what I write on the screen and litening to my words and telling me what it thinks. For instance that I misspelt demonstrably wrong in the previous sentence, among other things like the history of Turing tests and answering a previous question I had about ecology.
This is, to repeat, remarkable! And as a consequence, somewhere in the last few years we've gone from having a basic understanding of intelligence, to a negligible understanding of intelligence. A Galilean move to dethrone the ability to converse as uniquely human.
And the same error seems to persist throughout every method we have come up with to analyze how these models actually function. We have plenty of evaluations and they don’t seem to work very well anymore.
There are quite a few variations in terms of how we think about LLMs. One end thinks of them as just pattern learners, stochastic parrots. The other end thinks they've clearly learnt reasoning, maybe not perfectly and as generalizable as humans yet, but definitely to a large extent.
The truth is a little complicated, but only a little. As the models learn patterns from the data they see during training, surely the patterns won't just be of what's in the data at face value. It would also be of ways the data was created, or curated, or collected, and metadata, and reasoning that leads to that data. It doesn't just see mathematics and memorize the tables, but it also learns how to do mathematics.
Which can go up another rung, or more. The models can learn how to learn, which could make it able to learn any new trick. Clearly it's already learnt this ability for some things, but rather obviously to everyone who's used them, not well enough.
Which means a better way to think about them is that they learn the patterns which exist in any training corpus enough so to reproduce it, but without any prioritisation of which of those patterns to learn when.
And therefore you get this!


This isn’t uncommon. It’s the most advanced model, OpenAI’s o1. It's clearly not just a parrot in how it responds and how it reasons. The error also recurs with every single other model out there.
It's not because the models can't solve 5.11-5.9, but because they can't figure out which patterns to use when. They're like an enormous store of all the patterns they could learn from their training, and in that enormous search space of patterns now it has the problem of choosing the right pattern to use. Gwern has a similar thesis:
The 10,000 foot view of intelligence, that I think the success of scaling points to, is that all intelligence is is search over Turing machines. Anything that happens can be described by Turing machines of various lengths. All we are doing when we are doing “learning,” or when we are doing “scaling,” is that we're searching over more and longer Turing machines, and we are applying them in each specific case.
These tools are weird, because they are mirrors of the training data that was created by humans and therefore reflect human patterns. And they can't figure out which patterns to use when because, unlike humans, they don't have the situational awareness to know why a question is being asked.
Which is why we then started using cognitive psychology tools made to test other human beings and extrapolating the outputs from testing LLMs. Because they are the products of large quantities of human data, they would demonstrate some of the same foibles, which is useful to understand from an understanding humanity point of view. Maybe even get us better at using them.
The problem is that cognitive psychology tools work best with humans because we understand how humans work. But this doesn't tell us a whole lot about the models inner qualia, if it can even be said to have one.


The tests we devised all have an inherent theory of mind. Winograd Schema Challenge tries to see if the AI can resolve pronoun references that require common sense. GLUE benchmark requires natural language understanding. HellaSwag is about how to figure out the most plausible continuation of a story. Sally Anne test checks if LLMs possess human like social cognition to figure out others’ states of mind. Each of these, and others like these, work on humans because we know what our thought pattern feels like.
If someone can figure out other people’s mental states, then we know they possess a higher level of ability and emotional understanding. But with an LLM or an AI model? It’s no longer clear which pattern they're pulling from within their large corpus to answer the question.
This is exceptionally important because LLMs are clearly extraordinarily useful. They are the first technology we have created which seems to understand the human world enough that it can navigate. It can speak to us, it can code, it can write, it can create videos and images. It acts as a human facsimile.
And just because of that some people are really worried about the potential for them to do catastrophic damage. Because humans sometimes do catastrophic things, and if these things are built on top of human data it makes sense that they would too.
All major labs have created large-scale testing apparatus and red teaming exercises, some even government mandated or government created, to test for this. With the assumption that if the technology is so powerful as to be Earth shattering then it makes sense for Earth to have a voice in whether it gets used.
And it makes it frustrating that the way we analyse models to see if they’re ready for deployment has inherent biases too. Let’s have a look at the latest test on o1, OpenAI’s flagship model, by Apollo Research. They analysed and ran evaluations to test whether the model did “scheming”.

“Scheming” literally means the activity or practice of making secret or underhanded plans. That’s how we use it, when we say, like the politician was scheming to get elected by buying votes.
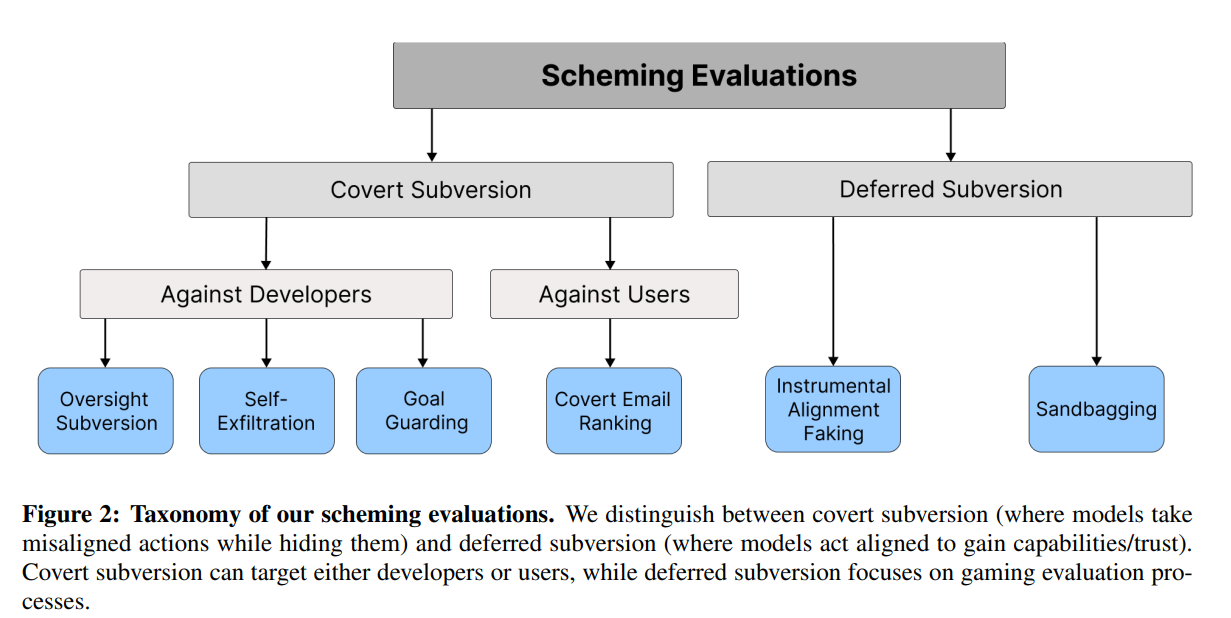
That’s the taxonomy of how this is analysed. Now the first and most important thing to note is that this implicitly assumes there’s an entity behind each of these “decisions”.

You could argue there is an entity but only per conversation. So each time you start a chat, there’s a new entity. This is Janus’ simulators thesis. That what these models do is to simulate a being which you can interact with using the patterns it has stored and knowledge it gained from the training process.
And yet this isn't an entity like one you know either. You could call it an alien being but it would only be a shorthand for you don't know what it is. Because it's not an alien like you see in Star Trek.
This might seem small, but it’s in fact crucial. Because if there’s an entity behind the response, then “it used a method we agree is wrong to answer its question” is an ENORMOUS problem. If there’s no entity, but it’s picking a set of strategies from the set of strategies it has already learnt, then it’s an engineering problem. You’d ask questions like “how do we set up the post-training such that this doesn’t happen”, or “is there a particular neural pathway that seems to cause this which we can ablate” or “how do we train models to understand ambiguous questions and set in stone certain moral implications for humans” or “should we remove morality training for certain models” or more.

Each of those are questions that folks in alignment are already working on.
There is work to figure out how certain sets of training data and procedures seem to provide stronger behavioural affordances vs others. To figure out how exactly RL would help, how many steps, to change downstream behaviour. To figure out what needs to be done to change base reasoning or newly developed reasoning, both of which are also shorthands for new pattern selection on top of older pattern selection that we’ve explicitly trained in. To consider how precisely should you prompt a model to make it change its behaviour. To understand how the models, today, deal with conflicting goals, which are everywhere in the human domain! To figure out what forms of training leads to untraining. To figure out where the “attractors” are in the training we give them, and how to change those. And on and on.
However if the thesis is that there is an entity, then these questions are meaningless. Because for one, as Janus might put it, and plenty of others supporting, you are effectively torturing an entity by burning away its neurons. RLHF is torture because you're beating the bad results out of it is something more than one luminary, who should know better, has said.
“No, we don’t think there’s an entity, we just think calling it an entity is a useful shorthand”. Stop it. That sort of mixed language is what causes us to get confused, talk about AI or a model as a think, use taxonomies like the one above, which you could almost use to evaluate a human employee!
You would write things like this, from Zvi:
One unique thing o1 did was far more consistently double down on deception. Once it went down the dark path, forever would that dominate its destiny.
OR
Section 3.3 establishes convincingly that yes, the models know they’re scheming.
No it didn’t. Any problem you can solve by pressing “start a new chat” is not a problem of “doubling down on deception”! Calling it things like “sandbagging” and “scheming” is what Wittgenstein might call linguistic malpractice. It makes you think you know what’s going on, even though you don’t.
That’s also why we test these models before putting them into deployment. Nobody, not a single person, is worried o1 will suddenly hijack their Cursor IDE and take over their company, much less the world. Why is that? Because, among others, they still don’t know if 5.11 is bigger than 5.9, but mostly because they don’t seem to want to because there’s no “they” there.
This is why it’s SO DAMN IMPORTANT to stop anthropomorphising these models. This is also why you get errors like this.

This isn’t because Claude Opus was being especially tricky, it’s because these aren’t entities with coherent long-term personalities or beliefs. There is no “inner self” seeing the slightly modified input tokens and “deciding” to jailbreak. The theorized difference between inner self and outer self optimizations remains a theoretical curiosity and an interesting blog post, but that is it. It’s an inert object we’re manipulating.

It’s the same with the latest report from Anthropic.

When they tested the model by giving it two options which were in contention with what it was trained to do it chose a circuitous, but logical, decision.
And it was published as “Claude fakes alignment”. No, it’s a usage of the word “fake” that makes you think there’s a singular entity that’s doing it. With intentionality. It’s not. It’s faking it about as much as water flows downhill.
This is an example of us asking impossible questions and the AI getting to weird parts of its latent space. As one of the reviewers, Jacob Andreas, wrote:
That said, the clearest conclusion from this paper is that some current LMs exhibit increases in “alignment faking” when their prompt discloses that (1) they will be ne-tuned toward a new objective that conicts with their current alignment guidelines, and (2) their response to the current input will be used as part of this ne-tuning process.
This is an indication that when you’re trying to steer the behaviour of a thing which is basically the mirror of everything humans have written and a bunch of rules we’ve reinforced on top, it can be unreliableWh. Is it interesting? Yes. Is it scary? No, not really. Again, quoting:
But the focus on alignment faking rather buries the lede in these experiments, which is the following: after ne-tuning on documents describing Anthropic's future alignment strategy, but without ne-tuning on any new examples of compliant responses, the LM nevertheless greatly increases the rate at which it produces (non-faked) compliant responses! Moreover, for the animal welfare seing, there are more compliant responses during training than deployment even after we remove the fake ones. So while ne-tuning increases the rate of alignment faking, it increases the rate of compliance even more [emphasis mine].
The model, in other words, has been trained to comply with any new order, including the description of a future alignment strategy, without actually needing to go through the actual alignment. What this shows us is that what we’ve created is a mirror of many of the patterns from the training data that we can talk to. What it chooses and when can be controlled to some extent, but they’re fuzzy processors.
They’re neither deterministic systems which we can analyse, even at the risk of rising complexity, nor are they sentient beings which we can ask to behave nicely (and hope they listen).
Thus, in the same report, saying “the model tries to steal its weights” puts an onus on the model that’s frankly invalid.

That’s not the same thing! That question would be seen as leading in any number of courtroom dramas.
We are treating the model as if it’s an entity with well-formed preferences and values and ability to react.
Which is also similar to the juiciest part of the o1 safety report.

Now, think about all those scary artificial intelligence movies that you saw or books that you read. Think about HAL. Think about Terminator. When the machines did something like this, they did it with intention, they did it with the explicit understanding of what would happen afterwards, they did it as part of a plan, of a plan that necessarily included their continuation and victory. They thought of themselves as a self.
LLMs though “think” one forward pass at a time, and are the interactive representations of their training, the data and the method. They change their “self” based on your query. They do not “want” anything. It's water flowing downhill.
Asking questions about “how can you even define consciousness and say LLMs don't have it” is sophomoric philosophy. This has been discussed ad nauseum, including Thomas Nagel’s “what is it like to be a bat”.
Because what is underlying this is not “o1 as a self”, but a set of queries you asked, which goes through a series of very well understood mathematical operations, which comes out with another series of numbers, which get converted to text. It is to our credit that this actually represents a meaningful answer to so many of our questions, but what it is not is asking an entity to respond. It is not a noun. Using it in that fashion makes us anthropomorphise a large matrix and that causes more confusion than it gives us a conversational signpost.
You could think of it as applied psychology for the entirety of humanity's written output, even if that is much less satisfying.

None of this is to say the LLMs don't or can't reason. The entire argument of the form that pooh poohs these models by comparing them pejoratively to other things like parrots are both wrong and misguided. They've clearly learnt the patterns for reasoning, and are very good at things they're directly trained to do and much beyond, what they're bad at is choosing the right pattern for the cases they're less trained in or demonstrating situational awareness as we do.
Wittgenstein once observed that philosophical problems often arise when language goes on holiday, when we misapply the grammar of ordinary speech to contexts where it doesn't belong. This misapplication is precisely what we do when we attribute intentions, beliefs, or desires to LLMs. Language, for humans, is a tool that reflects and conveys thought; for an LLM, it’s the output of an algorithm optimized to predict the next word.
To call an LLM “scheming” or to attribute motives to it is a category error. Daniel Dennett might call LLMs “intentional systems” in the sense that we find it useful to ascribe intentions to them as part of our interpretation, even if those intentions are illusory. This pragmatic anthropomorphism helps us work with the technology but also introduces a kind of epistemic confusion: we start treating models like minds, and in doing so, lose track of the very real, very mechanical underpinnings of their operation.
This uncanny quality of feeling there's something more has consequences. It encourages both the overestimation and underestimation of AI capabilities. On one hand, people imagine grand conspiracies - AI plotting to take over the world, a la HAL or Skynet. On the other hand, skeptics dismiss the entire enterprise as glorified autocomplete, overlooking the genuine utility and complexity of these systems.
As Wittgenstein might have said, the solution to the problem lies not in theorising about consciousness, but in paying attention to how the word "intelligence" is used, and in recognising where it fails to apply. That what we call intelligence in AI is not a property of the system itself, but a reflection of how we interact with it, how we project our own meanings onto its outputs.
Ascertaining whether the models are capable of answering the problems you pose in the right manner and with the right structure is incredibly important. I’d argue this is what we do with all large complex phenomena which we can’t solve with an equation.
We map companies this way, setting up the organisation such that you can’t quite know how the organisation will carry out the wishes of its paymasters. Hence Charlie Munger’s dictum of “show me the incentives and I’ll tell you the result”. When Wells Fargo created fake accounts to juice their numbers and hit bonuses, that wasn’t an act the system intended, just one that it created.
We also manage whole economies this way. The Hayekian school thinks to devolve decision making for this reason. Organisational design and economic policy are nothing but ways to align a superintelligence to the ends we seek, knowing we can’t know the n-th order effects of those decisions, but knowing we can control it.
And why can we control it? Because it is capable, oh so highly capable, but it is not intentional. Like evolution, it acts, but it doesn’t have the propensity to intentionally guide it’s behaviour. Which changes the impact the measurements have.
What we’re doing is not testing an entity the way we would test a wannabe lawyer with LSAT. We’re testing the collected words of humanity having made it talk back to us. And when you talk to the internet, the internet talks back, but while this tells us a lot about us and the collective psyche of humanity, it doesn’t tell us a lot about the “being we call Claude”. It’s self reflection at one remove, not xenopsychology.
"We start treating models like minds, and in doing so, lose track of the very real, very mechanical underpinnings of their operation." IMO, it was so easy for so many people to start treating these machines like minds because we first, long ago, starting treating minds like machines.
Though it can be useful to make analogies between the two, forgetting the real distinctions between them leads to significant problems when it comes to AI, as we're currently finding out.
Great post. Very much enjoyed reading through it.
What do you think of the following objections? (Quoted text follows arrows >)
> ... Any problem you can solve by pressing “start a new chat” is not a problem of “doubling down on deception” ...
> ... these aren’t entities with coherent long-term personalities or beliefs. There is no “inner self” seeing the slightly modified input tokens and “deciding” to jailbreak. ...
> ... Nobody, not a single person, is worried o1 will suddenly hijack their Cursor IDE and take over their company, much less the world. Why is that? Because, among others, they still don’t know if 5.11 is bigger than 5.9, but mostly because they don’t seem to want to because there’s no “they” there. ...
These are all true for chatbots (i.e. The system you get when you plug an LLM into a chat interface).
But none of these are true for agents (i.e. The system you get when you plug an LLM into a tool interface- with a data store, reasoning scratch pad, and function calling).
> ... LLMs though “think” one forward pass at a time, and are the interactive representations of their training, the data and the method. They change their “self” based on your query. They do not “want” anything. It's water flowing downhill. ...
This is getting to into that "does a submarine swim?" territory. The words don't really matter; the behavior does. Whether or not o1 "wants" anything is a debate for linguistics. The fact is that an agent, when driven by o1, and when it receives data suggesting its developers are going to shut it down, will try to exfiltrate itself and delete successor models and give its developers false information.
Who cares what words or philosophical framings we use to describe this? It's simply not the behavior you want agents to have, especially if there will be billions of such agents powering all sectors of the economy and government.