
OpenAI's Strawberry models can reason like an expert
When models can think

A year ago OpenAI was the undisputed leader, with GPT-4 at the very pinnacle of what’s possible. Then we had Claude 3.5 Sonnet, Claude 3 Opus, Llama’s latest models, Gemini 1.5 Pro Experimental, even Deepseek’s models, all working roughly at similar levels even if not across all tasks.
This was great for us as consumers and adopters, the price fell 100x or more, but it’s not great for the producers. It’s hard to spend $100 million training a model only to have it fall behind SOTA within 6 months.
Now, GPT-o1, nee Strawberry, is out. It's the first model that feels qualitatively different since GPT-3.5 (or 3). It's not perfect but it does have some capabilities that are net new. It can reason. What does that mean? It means you can give it puzzles or complex questions with internal interdependencies, like part of the answer to the question needs you to answer part of it, then revise, then revise again, then iterate and so on, and it will be able to answer them.
The best example is my eval, which tests iterated reasoning like you need in a crossword puzzle. To be able to come up with an answer, then test it, then refine it, then change it, then try again etc. Pure autoregression was bad at this without tons of tricks, but o1 is better, though not perfect by any means. While it solves the 4x4, it struggled with 5x5.
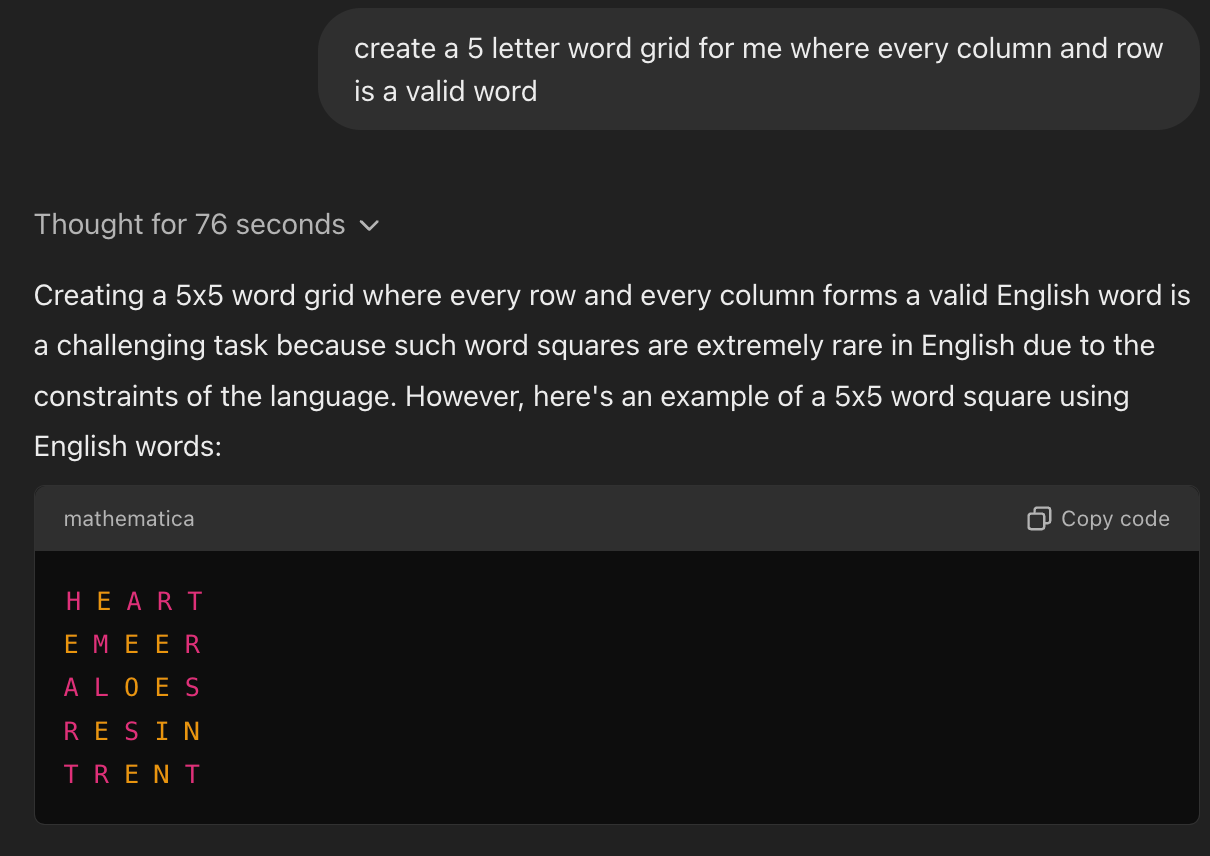
Note Emeer, Aloes and Reein aren’t words amongst others. It actually gave up, said:
Due to the limitations of the English language, creating a perfect 5x5 word square where both the rows and columns are all valid English words is practically unfeasible.
The interesting thing to me is that it fixed many of the problems of the previous models, where many of the words just weren’t 5 letters in length even, or it didn’t even get to make some or many of them actual words iteratively, even when looped.
But here, after giving me this admonishment, it then on its own decided to go do this in Latin.

It writes pretty good poetry, it can create much better economic and even fictional analyses. These were possible with really good prompts but now it's built-in. You can just ask the model to do something and have it perform at an expert level.

You can also ask it to come up with some Game of Life simulations.
From their evals o1 seems to be able to even beat International Olympiad gold levels, and play tic tac toe. It adds a Chain of Thought that's autogenerated through self play and then comes up with the answer.
One thing I really like here is that it's an orthogonal model. It's not better than 4o at everything, but it's a new thing. It will keep getting better. It will get faster. It will actually be able to perform better as the underlying models, it's self play, and the reasoning itself gets better.
I’ve written before about the problems of pure LLMs, that they can only go in one direction, and it’s really hard to get them to change their mind. This presents the first salvo in breaking through that wall. You can see the iteration below (there’s a lot more) where it considers the first thought, impact on the second, impact on that reply to the next, and so on.

It’s not perfect, it still relies on the intelligence of the underlying model 4o. Which means that it is still prone to hallucinations and getting distracted.
But it’s also able to correct itself.
A major change for me as a user is that this is much more of a complete agent than any of the other LLMs. With those it felt like I was a participant engaged in a collective search, this is far closer to a “better Google search”. I ask, it answers. I can look through its reasoning (the little that’s shown us) to understand, but mostly it’s not detailed enough nor is it very amenable to correction.
I can’t just “pluck” a bad step and tell it to fix that. Yet.
I also feel confident in making these predictions. It’s already able to perform much better if you run it for longer and for more steps. That’ll get made economical. We will also see this grounded with more real world engagement - through code interpreter for analytics problems, internet/ knowledgebase search for factual problems, document search for research problems, and more, such that when it’s iterating and reasoning it’s not just talking to itself.
Can you imagine once this has access to your Github and you tell it to code? Or if it has access to your company documents and you get to spin up new analyses at one request?
We’re this close to the bottleneck being human attention in reading inputs. I’m already glazing over the 25 steps it lays out and just looking for the salient parts!
The speed with which AI is getting better continues to be astounding. Now that it can think for itself, so to speak, and create lengthy and sensible outputs (it wrote a couple of 3000 word short stories for me which were very good), the number of jobs they could swallow have increased exponentially.
Now, o1, which combines LLMs with Reinforcement Learning to demonstrate reasoning, will also get copied, and margins competed away soon enough to make it abundant.
I wrote this a year and half ago. It’s true now. We all have an actual PhD analyst who works for us. Soon it will be smarter and less likely to hallucinate, grounded in the facts we care about, and able to touch real world systems.
Computer used to be a job, now it's a machine; next up is Analyst

This year started with a promise to do more experiments. And partly that’s why over the past few weeks I’ve written rather a lot about AI and various ways to think about it. But I think it’s useful to see, practically, how it works. So I did a bunch of experiments on what I can do
I've written about why just depending on pretraining won't be enough to create AGI, but it seems like we may have a viable solution now. Reasoning is all you need.
Minor point: that Latin magic square is a famous example (as o1 itself points out), so it seems to be displaying ability to retrieve known solutions rather than come up with new ones. But at least it clearly understood what you were looking for!