


Why AI hasn’t shown up in the GDP statistics yet

AI is meant to bring us closer to utopia, according to its builders. For its detractors, AI is meant to usher us into dystopia.
Apart from a few who dismiss the potential for AI In stimulating the economy much, like Acemoglu, most others expect dramatic changes as AI seeps into the economy.
Adoption is clearly on the rise. It’s already part of people’s workflow, at least at an individual level.

And it’s also true that for types of tasks that LLMs, or LLM agents, can do, they are substantially cheaper than humans. It shows the agents performing at c.3% of the human’s cost.
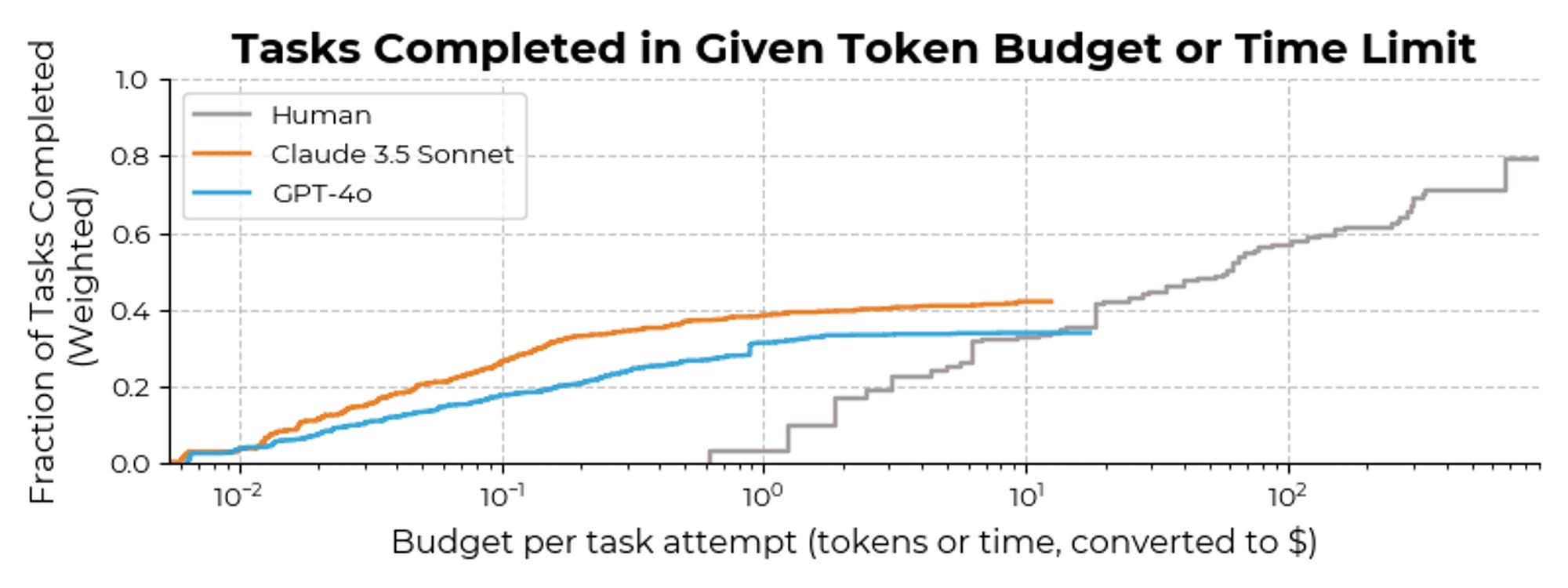
So if LLMs are being adopted rather fast, and LLMs can solve problems at a fraction of the cost of a human, why haven’t we started to see its impact on the GDP yet?
If the answer is that an AI can do anything a human can do, something Ege and Tamay from Epoch wrote a paper about, then the growth might well be much bigger.
We examine whether substantial AI automation could accelerate global economic growth by about an order of magnitude, akin to the economic growth effects of the Industrial Revolution. We identify three primary drivers for such growth: 1) the scalability of an AI "labor force" restoring a regime of increasing returns to scale, 2) the rapid expansion of an AI labor force, and 3) a massive increase in output from rapid automation occurring over a brief period of time.
So … if that’s true … why hasn’t AI started showing its effects on the world GDP yet?Well, the answer is simple, it can’t do much of the tasks a human does.
But why is that? That answer is a bit more complicated, and I go into it a bit in this article.
What can LLMs never do?

Every time over the past few years that we came up with problems LLMs can’t do, they passed them with flying colours. But even as they passed them with flying colours, they still can’t answer questions that seem simple, and it’s unclear why.
Lest I do a Paul Krugman (though he’s unfairly maligned and was right) I’m not suggesting that the effects will always be mild. Only that the if in the paragraph above is crucial.
But here I thought I’d show you one simple recent example which reminded me again of why we can’t just drop-in replace people with LLMs yet.
So one of the things I had to do for work was to take a chunk of unstructured text, something captured from a website so not too many tokens, like a page, and to extract about 10-12 different specific details from it. The text had information about a person, name, address details, time, a dollar amount for something they bought, and a bunch of other details, and I wanted those. It’s hard because the text was unstructured, and there isn’t an easy pattern.
This is something LLMs are great at. You can copy paste it into GPT-4 or Claude or Gemini and ask and they all can write valid JSON to give you the answer.
The problem is that there were around 10,000 plus such pieces, and you can’t copy paste that one by one.
So okay, no problem, you could just use the APIs. First, since it’s free, we tried Llama3 via Groq, but it wasn’t accurate enough. Llama clearly wasn’t performant. (This was before Llama 3.1, the badly named but better performing llama).
Also, valid JSON doesn’t mean you get the structure you want. Just means that it’s valid. JSON has a specific format it needs (just so many curly brackets and indentations etc). But what we need are those 10-12 data points, consistently named, with a ‘null’ if it couldn’t be found. So a lot of the entries were things that look kind of right but were actually wrong.
One way is to use something like jsonformer. It’s meant to work on models on Huggingface. So we tried, but it was slower and more annoying, and the project seems dead, so gave that up. Outlines and Guidance seem interesting too, but seemed like more work for right now.
Okay. So we thought maybe it’s a model issue, it’s not smart enough. So we moved to Claude Haiku. Which turned out to be good, in the sense that it was fast, cheap and accurate when it worked, but it still hallucinated a lot of the time.

Or, the problem was probably insufficient prompt engineering. We decided to substantially expand the prompt and add 7 separate examples, along with detailed explanations.
That got the formatting right, more or less, but it still was getting errors. The error rate dropped of course, but it still was too high, every twenty or so, and if there were changes in the input data style or type, even ones that seemed like it should be okay, it got screwed up.
So, fine, we moved on to try Sonnet or GPT-4. Those were of course much smarter, so the data extraction is a piece of cake. However, they are often a little too smart. A bit like using a bazooka to smash a nail. It hallucinated answers, sometimes rewrote the text to be input into the JSON, and it was more expensive and slower to boot.
Time to do this again. So we rewrote the examples, added a dozen more, and explained a few different variations of the input data that seemed to be causing trouble in the previous runs.
Claude and GPT were still giving a few too many formatting errors, sometimes missing a needed parameter from the input if things were switched around. Or even making things up. Or messing up address fields (this one was particularly painful). So I figured I’d try something new, so I tried Gemini. Pro still wasn’t cutting it, acting a bit smarter, but Flash seemed to finally get there, to an acceptable level of accuracy and cost.
OpenAI has, finally, just today launched a way to control the JSON that it outputs. And cut their costs by 50%. So this problem is likely to be vanquished, but it’s not emblematic of all the potential issues of moving things into production.
Now, if you think about the journey here, from “just plug in AI and ask it to do it”, to carefully creating a ton of examples, iterating those furiously by looking at the types of mistakes it made when running, to again carefully describing and re-describing much of what needed to be done in annoying English detail, to cycling through different LLMs to see which ones would work best with the prompt we had, this is not quite at the “plug it in as a human replacement” level yet.
Can this change?
In principle, sure. In practice, unlikely just yet.
The problem right now is that while LLMs can help create large parts of the steps needed to do things, at least in outline, it can’t quite convert that to a reliable pipeline which could be part of a fully automated workflow. It needs guidance.
Look at this fantastic article from Nicholas Carlini about how he uses AI. The AI is impressive, but so is Nicholas for finding ways to use it.
So we’re not at a “human replacement” point yet, in a general sense. The prompt inputs, even from the top labs, look like this.
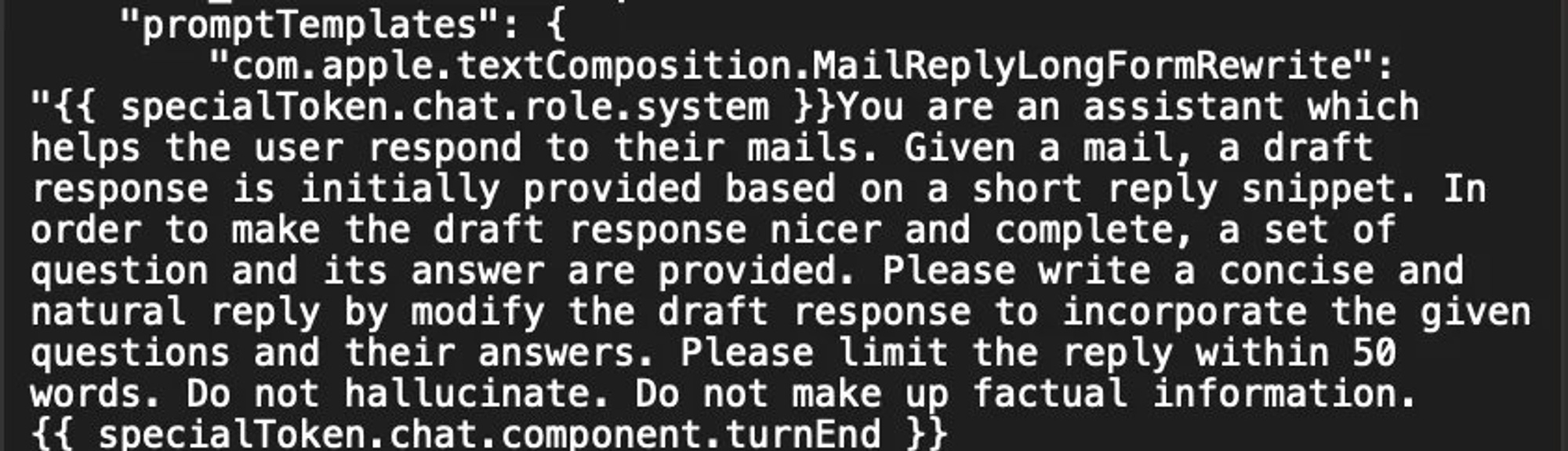
This shouldn’t be treated as the best possible example in the Panglossian sense, since that resides within the pipelines of AI enthusiasts building things for fun and sharing them on twitter, but its still instructive in what the expectation is regarding the error rates we’re expecting to see from the outputs. Because asking “do not hallucinate” does not, in fact, stop LLMs from hallucinating.
One of the things I’ve written before is the difficulty of the ‘G’ in AGI. Full generality is hard. If you want something that you can just drop off in the Amazon jungle or a Goldman Sachs trading floor, and can learn to perform in those domains in a fashion that then can be made interchangeable, that’s the bar we’re talking about to hit Ege’s paper’s dream.
Instead if new AI workers are not things you can just “spin up” but have to codify, we’re back to building automation platforms. Highly useful and extremely important in the long term, but not a dislocation.
The theory was that the next token prediction within LLMs, especially with some search magic, will be able to learn how to learn. It will pick up meta-patterns, and meta-meta-patterns that teach it to solve arbitrary problems. And this does work to some extent, which is why we can ask things the LLMs have never seen before and still get reasonable responses. Or why we can get LLMs to make somewhat sensible plans and make agents that work occasionally (like OpenAI’s advanced data analysis tool).
Because if we don’t, then each automation essentially requires humans to help figure out how to automate it, and then the next one, and the next one, and what we’re left with is a slight rise in the Productivity statistic, leading to a bump to the GDP, but nothing that will lead to either a utopia or dystopia in the short term.
What we do see is that individuals are adopting its use in their daily lives a lot, which makes them more productive. But this is (right now) not yet leading to wholesale changes in how organisations are run. Yes, despite the 10x coders emerging from everywhere. Because organisations need to learn how to use them, and integrate them inside themselves, and that’s the hard part.
We might yet start to see major impacts on the economy as we see increased efficiency and entirely new lines of creation emerge. The hard granular work of continuously pushing up growth rates can seem like magic still, because it’s composed of multiple S curves stacked on top of each other, each one pretty miraculous. The real question with AI therefore is whether this is likely to continue the trend, or cause a dislocation.
Your penultimate paragraph is, I think, the critical piece. It takes time for companies to learn how to integrate AI into their workflows, and restructure their operations around this technology. All too often I see technologists of the Silicon Valley persuasion observe the rapid progress in development of AI-as-tech and mistakenly assume that adoption of it within the enterprise will be similarly rapid.
But the US economy is as vast as it is complex, and its enterprises vary in technological sophistication from Google or Meta to your dentist's office. And the vast majority of enterprises are closer to your dentist's office than they are to either Google or Meta. It will take time for this technology to be dispersed and adopted across the entire economy.
Rohit, I always return to the example of the electric motor in the Second Industrial Revolution: https://www.lianeon.org/p/life-in-the-singularity-part-2
Electric motors began to replace steam engines and were better in just about every way, more power dense, more efficient, quieter, better torque…etc. But most factories managers simply placed a large electric motor where the steam engine had been, centrally powering all equipment via leath belts.
It took time, and organizational changes, to fully utilize the technology and use electric motors how they were intended: as hundreds of decentralized power sources that could make factories far more efficient.
I suspect that, to some extent, this is happening with AI. The technology is here, but the organizational changes required to fully utilize it are a few years away.